Knowledge Graphs
References and useful ressources
- https://learn.deeplearning.ai/courses/knowledge-graphs-rag
- https://docs.llamaindex.ai/en/stable/examples/index_structs/knowledge_graph/Neo4jKGIndexDemo.html
What is a Knowledge Graph ?
This is a database that stores information in Nodes and Relationships.
- Nodes (or Vertices) and Relationships (or Edges) are data records
- Nodes and Relationships have key/value properties
- Nodes can be given a label to group them together (e.g. Person, Course, ...)
- Relationship always have a type (e.g. KNOWS, TEACHES, ...) and a direction
- Nodes are IN a Relationship (they aren't just keys shared between 2 tables)
- There can be several Relationships between two Nodes
- There can be a Relationship linking a Node to itself
- Graph types are composable
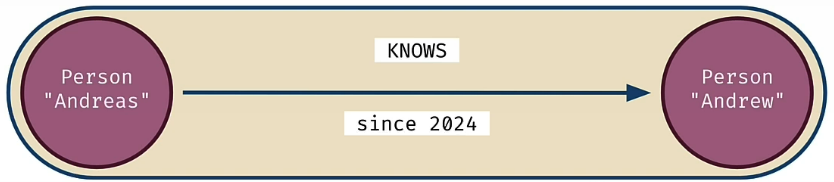
Here is a simple Graph with 2 Nodes and 1 Relationship
(Person)-[KNOWS]->(Person)
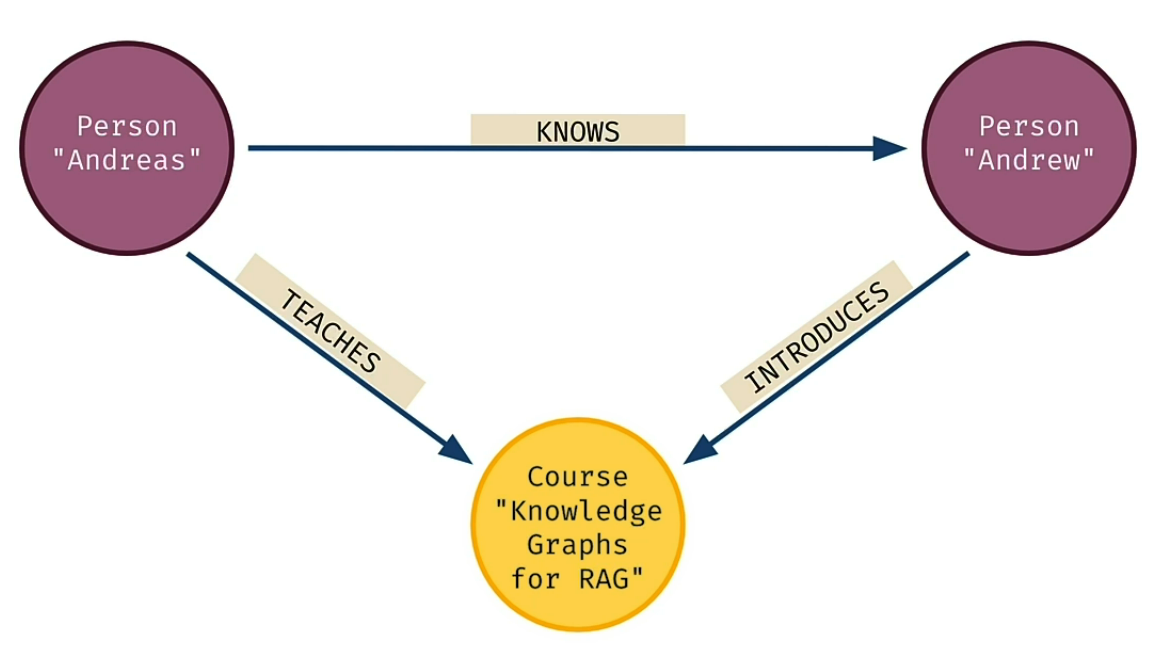
Here is a more advanced Graph with 3 Nodes and 3 Relationships
(Person)-[KNOWS]->(Person)
(Person)-[TEACHES]->(Course)<-[INTRODUCES]-(Person)
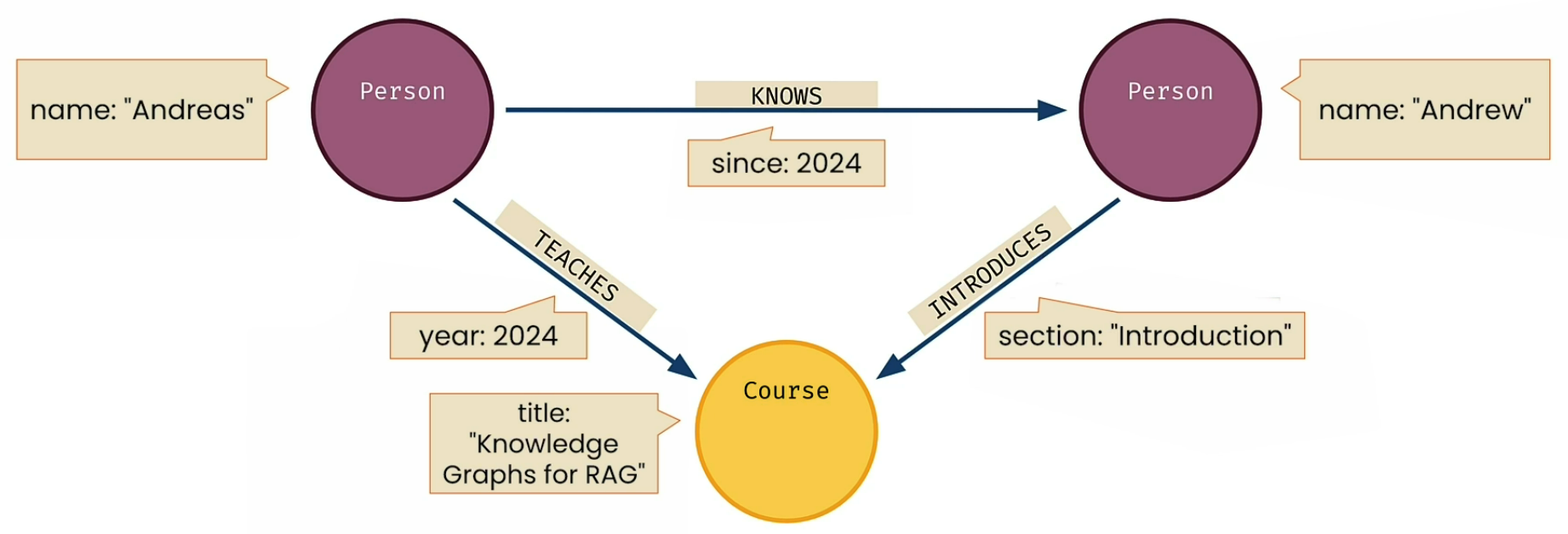
And here is the Graph with all the properties, labels and directions
(a:Person {name:'Andreas'})
(b:Person {name:'Andrew'})
(c:Course {title:'Knowledge Graphs for RAG'})
(a)-[KNOWS {since: 2024}]->(b)
(a)-[TEACHES {year: 2024}]->(c)<-[INTRODUCES {section:'introduction'}]-(b)
Querying a Graph with Cypher
Cypher is Neo4j's declarative query language
Count all nodes
MATCH (n)
RETURN count(n)
Count all nodes matching a given Label
MATCH (people:Person)
RETURN count(people) AS numberOfPeople
Find all nodes matching a given Label
MATCH (people:Person)
RETURN people
Find a node matching a given Label and a given Property
MATCH (tom:Person {name:"Tom Hanks"})
RETURN tom
⚠️ Cyher is case-sensitive, so we have to use WHERE n.property =~'(?i)({param})
MATCH (tom:Person)
WHERE tom.name =~ '(?i)tom hanks'
RETURN tom
Find a node matching a given Label and a given Property then return a specific Property
MATCH (cloudAtlas:Movie {title:"Cloud Atlas"})
RETURN cloudAtlas.released
Find all nodes matching a given Label and return specific Properties
MATCH (movies:Movie)
RETURN movies.title, movies.released
Find all Relationships
MATCH ()-[r]-()
RETURN r
Find all Relationships given a node Label
MATCH (:Person)-[r]-()
RETURN r
Find all Relationships for a given Node
MATCH (:Person {name:'Tintin'})-[r]-()
RETURN r
Conditional matching
MATCH (nineties:Movie)
WHERE nineties.released >= 1999
AND nineties.released < 2000
RETURN nineties.title
Joint
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)
RETURN actor.name, movie.title LIMIT 10
Joint with a given Label
MATCH (tom:Person {name: "Tom Hanks"})-[:ACTED_IN]->(tomHanksMovies:Movie)
RETURN tom.name,tomHanksMovies.title
Multi-directional Joint
MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors)
RETURN coActors.name, m.title
Delete a Relationship
MATCH (emil:Person {name:"Captain Haddock"})-[actedIn:ACTED_IN]->(movie:Movie)
DELETE actedIn
Delete a Node
MATCH (emil:Person {name:"Captain Haddock"})
DELETE actedIn
⚠️ To delete a Node you need to delete it's Relationships first
Create a Node
CREATE (tintin:Person {name:"Titin"})
RETURN tintin
Create a Relationship
MATCH (tintin:Person {name:"Tintin"}), (emil:Person {name:"Milou"})
MERGE (tintin)-[hasRelationship:WORKS_WITH]->(milou)
RETURN tintin, hasRelationship, milou
Create a constraint on a Label
CREATE CONSTRAINT unique_person IF NOT EXISTS
FOR (p:Person) REQUIRE p.name IS UNIQUE
Create a Fulltext index on a Label
CREATE FULLTEXT INDEX fullTextPersonNames IF NOT EXISTS
FOR (p:Person) ON EACH [p.name]
Query a Fulltext index (similar to querying vector index)
CALL db.index.fulltext.queryNodes("fullTextPersonNames", "Tintin")
YIELD node, score
RETURN node.name, score
Create a Node if it doesn't exists
MERGE(mergedP:Person {name:'Tintin'})
ON CREATE SET
mergedP.age = 35,
RETURN mergedP
⚠️
MERGE tries to find the element and create it if it can't be found.
CREATE directly tries to create the element and hence it is a lot faster.
Multi MATCH conditions
MATCH (c:Chunk {chunkId: $chunkIdParam})-[:PART_OF]->(f:Form),
(com:Company)-[:FILED]->(f),
(mgr:Manager)-[:OWNS_STOCK_IN]->(com)
RETURN com.companyName, count(mgr.managerName) as numberOfinvestors
⚠️ In this exemple the multiple MATCH elements will create constraints between themselves.
The Form f retrieved on the first constraint is used to retrieve the Company com which is in turn used to retrieve the Manager mgr.
Display the existing Graph indexes
SHOW INDEXES
Querying a Graph as a VectorDB
Create a Vector-index
CREATE VECTOR INDEX movie_tagline_embeddings IF NOT EXISTS
FOR (m:Movie) ON (m.taglineEmbedding)
OPTIONS { indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
Display Vector-index information
SHOW VECTOR INDEXES
Create Embeddings for a given node Property
kg.query("""
MATCH (movie:Movie) WHERE movie.tagline IS NOT NULL
WITH movie, genai.vector.encode(
movie.tagline,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS vector
CALL db.create.setNodeVectorProperty(movie, "taglineEmbedding", vector)
""",
params={"openAiApiKey":OPENAI_API_KEY, "openAiEndpoint": OPENAI_ENDPOINT} )
Check one Embedding
MATCH (m:Movie)
WHERE m.tagline IS NOT NULL
RETURN m.tagline, m.taglineEmbedding
LIMIT 1
Apply similarity search on the Vector-index
question = "What movies are about adventure?"
kg.query("""
WITH genai.vector.encode(
$question,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS question_embedding
CALL db.index.vector.queryNodes(
'movie_tagline_embeddings',
$top_k,
question_embedding
) YIELD node AS movie, score
RETURN movie.title, movie.tagline, score
""",
params={"openAiApiKey":OPENAI_API_KEY,
"openAiEndpoint": OPENAI_ENDPOINT,
"question": question,
"top_k": 5
})
Examples of advanced queries
Which city in California has the most companies listed?
MATCH p=(:Company)-[:LOCATED_AT]->(address:Address)
WHERE address.state = 'California'
RETURN address.city as city, count(address.city) as numCompanies
ORDER BY numCompanies DESC
What are top investment firms in San Francisco?
MATCH p=(mgr:Manager)-[:LOCATED_AT]->(address:Address), (mgr)-[owns:OWNS_STOCK_IN]->(:Company)
WHERE address.city = "San Francisco"
RETURN mgr.managerName, sum(owns.value) as totalInvestmentValue
ORDER BY totalInvestmentValue DESC
LIMIT 10
Which companies are within 10 km around Santa Clara?
MATCH (sc:Address)
WHERE sc.city = "Santa Clara"
MATCH (com:Company)-[:LOCATED_AT]->(comAddr:Address)
WHERE point.distance(sc.location, comAddr.location) < 10000
RETURN com.companyName, com.companyAddress
Which investment firms are within 10 km around company ABC?
CALL db.index.fulltext.queryNodes(
"fullTextCompanyNames", "ABC"
) YIELD node, score
WITH node as com
MATCH (com)-[:LOCATED_AT]->(comAddress:Address),
(mgr:Manager)-[:LOCATED_AT]->(mgrAddress:Address)
WHERE point.distance(comAddress.location, mgrAddress.location) < 10000
RETURN mgr,
toInteger(
point.distance(comAddress.location, mgrAddress.location) / 1000
) as distanceKm
ORDER BY distanceKm ASC
LIMIT 10
Example of an LLM app with RAG based on a graph
Create a Neo4j Graph RAG app using LangChain
Prepare the data as a list of dictionaries
def split_form10k_data_from_file(file):
chunks_with_metadata = [] # use this to accumlate chunk records
file_as_object = json.load(open(file)) # open the json file
for item in ['item1','item1a','item7','item7a']: # pull these keys from the json
print(f'Processing {item} from {file}')
item_text = file_as_object[item] # grab the text of the item
item_text_chunks = text_splitter.split_text(item_text) # split the text into chunks
chunk_seq_id = 0
for chunk in item_text_chunks[:20]: # only take the first 20 chunks
form_id = file[file.rindex('/') + 1:file.rindex('.')] # extract form id from file name
# finally, construct a record with metadata and the chunk text
chunks_with_metadata.append({
'text': chunk,
# metadata from looping...
'f10kItem': item,
'chunkSeqId': chunk_seq_id,
# constructed metadata...
'formId': f'{form_id}', # pulled from the filename
'chunkId': f'{form_id}-{item}-chunk{chunk_seq_id:04d}',
# metadata from file...
'names': file_as_object['names'],
'cik': file_as_object['cik'],
'cusip6': file_as_object['cusip6'],
'source': file_as_object['source'],
})
chunk_seq_id += 1
print(f'\tSplit into {chunk_seq_id} chunks')
return chunks_with_metadata
first_file_name = "./data/form10k/0000950170-23-027948.json"
first_file_chunks = split_form10k_data_from_file(first_file_name)
Prepare the Knowledge Graph (without Vector-indexes)
# Initialize the LangChain Neo4j graph
kg = Neo4jGraph(
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE
)
# Create a UNIQUE constraint on the Chunk nodes
kg.query("""
CREATE CONSTRAINT unique_chunk IF NOT EXISTS
FOR (c:Chunk) REQUIRE c.chunkId IS UNIQUE
""")
# Define the merge query to insert Chunk nodes
merge_chunk_node_query = """
MERGE(mergedChunk:Chunk {chunkId: $chunkParam.chunkId})
ON CREATE SET
mergedChunk.names = $chunkParam.names,
mergedChunk.formId = $chunkParam.formId,
mergedChunk.cik = $chunkParam.cik,
mergedChunk.cusip6 = $chunkParam.cusip6,
mergedChunk.source = $chunkParam.source,
mergedChunk.f10kItem = $chunkParam.f10kItem,
mergedChunk.chunkSeqId = $chunkParam.chunkSeqId,
mergedChunk.text = $chunkParam.text
RETURN mergedChunk
"""
# Create Chunk nodes
node_count = 0
for chunk in first_file_chunks:
print(f"Creating `:Chunk` node for chunk ID {chunk['chunkId']}")
kg.query(merge_chunk_node_query, params={'chunkParam': chunk})
node_count += 1
print(f"Created {node_count} nodes")
Create the Vector-index and compute the chunk embeddings
# Initialize the Vector-index
kg.query("""
CREATE VECTOR INDEX `form_10k_chunks` IF NOT EXISTS
FOR (c:Chunk) ON (c.textEmbedding)
OPTIONS { indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
""")
# Create and insert embeddings for the Chunk texts
kg.query("""
MATCH (chunk:Chunk) WHERE chunk.textEmbedding IS NULL
WITH chunk, genai.vector.encode(
chunk.text,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS vector
CALL db.create.setNodeVectorProperty(chunk, "textEmbedding", vector)
""",
params={"openAiApiKey":OPENAI_API_KEY, "openAiEndpoint": OPENAI_ENDPOINT} )
# Show the existing indexes (tables)
kg.query("SHOW INDEXES")
Create the LangChain app and ask questions
# Initialize the LangChain Neo4j Vector-index (with embedding)
neo4j_vector_store = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=VECTOR_INDEX_NAME,
node_label=VECTOR_NODE_LABEL,
text_node_properties=[text],
embedding_node_property='textEmbedding',
)
# Create a retriever from the vector store
retriever = neo4j_vector_store.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever
)
# Create a function to pretty print the chain's response to a question
def prettychain(question: str) -> str:
response = chain({"question": question},
return_only_outputs=True,)
print(textwrap.fill(response['answer'], 60))
# Ask a question
prettychain("""
Tell me about Apple.
Limit your answer to a single sentence.
If you are unsure about the answer, say you don't know.
""")
Adding Relationships to the Knowledge Graph
Create the main document node (we need one per doc)
# Get useful information from a random Chunk node
cypher = """
MATCH (anyChunk:Chunk)
WITH anyChunk LIMIT 1
RETURN anyChunk { .names, .source, .formId, .cik, .cusip6 } as formInfo
"""
form_info_list = kg.query(cypher)
form_info = form_info_list[0]['formInfo']
# Create the main doc node from the collected information
cypher = """
MERGE (f:Form {formId: $formInfoParam.formId })
ON CREATE
SET f.names = $formInfoParam.names
SET f.source = $formInfoParam.source
SET f.cik = $formInfoParam.cik
SET f.cusip6 = $formInfoParam.cusip6
"""
kg.query(cypher, params={'formInfoParam': form_info})
Connect chunks as a linked list with NEXT type
# Create the query used to link the nodes
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam
WITH from_same_section
ORDER BY from_same_section.chunkSeqId ASC
WITH collect(from_same_section) as section_chunk_list
CALL apoc.nodes.link(
section_chunk_list,
"NEXT",
{avoidDuplicates: true}
)
RETURN size(section_chunk_list)
"""
# Loop over all sections and create the links between their associated chunks
for form10kItemName in ['item1', 'item1a', 'item7', 'item7a']:
kg.query(cypher, params={
'formIdParam':form_info['formId'],
'f10kItemParam': form10kItemName
})
Connect chunks to their parent form with the PART_OF type
cypher = """
MATCH (c:Chunk), (f:Form)
WHERE c.formId = f.formId
MERGE (c)-[newRelationship:PART_OF]->(f)
RETURN count(newRelationship)
"""
kg.query(cypher)
Connect the main doc node to the first node of each linked-list with a SECTION type
cypher = """
MATCH (first:Chunk), (f:Form)
WHERE first.formId = f.formId
AND first.chunkSeqId = 0
WITH first, f
MERGE (f)-[r:SECTION {f10kItem: first.f10kItem}]->(first)
RETURN count(r)
"""
kg.query(cypher)
Querying using the Nodes and Relations
Query the first node of a given section of the document
cypher = """
MATCH (f:Form)-[r:SECTION]->(first:Chunk)
WHERE f.formId = $formIdParam
AND r.f10kItem = $f10kItemParam
RETURN first.chunkId as chunkId, first.text as text
"""
first_chunk_info = kg.query(cypher, params={
'formIdParam': form_info['formId'],
'f10kItemParam': 'item1'
})[0]
Query the node following a given node in the linked-list
cypher = """
MATCH (first:Chunk)-[:NEXT]->(nextChunk:Chunk)
WHERE first.chunkId = $chunkIdParam
RETURN nextChunk.chunkId as chunkId, nextChunk.text as text
"""
next_chunk_info = kg.query(cypher, params={
'chunkIdParam': first_chunk_info['chunkId']
})[0]
Query a window of 3 nodes around a given node
cypher = """
MATCH (c1:Chunk)-[:NEXT*0..1]->(c2:Chunk)-[:NEXT*0..1]->(c3:Chunk)
WHERE c2.chunkId = $chunkIdParam
RETURN c1.chunkId, c2.chunkId, c3.chunkId
"""
kg.query(cypher, params={'chunkIdParam': next_chunk_info['chunkId']})
⚠️ [:NEXT*0..1] means that we want between 0 and 1 nodes on this side of the Relation
Retrieving the actual size of the window (or longest path)
cypher = """
MATCH window=(:Chunk)-[:NEXT*0..1]->(c:Chunk)-[:NEXT*0..1]->(:Chunk)
WHERE c.chunkId = $chunkIdParam
WITH window as longestChunkWindow
ORDER BY length(window) DESC LIMIT 1
RETURN length(longestChunkWindow)
"""
kg.query(cypher, params={'chunkIdParam': first_chunk_info['chunkId']})
Customising the results of the LangChain similarity search
# Create a retrieval query with some extra text on top of the retrieved text
retrieval_query_extra_text = """
WITH node, score, "Andreas knows Cypher. " as extraText
RETURN extraText + "\n" + node.text as text,
score, node {.source} AS metadata
"""
# Create the LangChain Neo4j vector store
vector_store_extra_text = Neo4jVector.from_existing_index(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=text,
retrieval_query=retrieval_query_extra_text,
# 'retrieval_query' replace 'embedding_node_property' in this case
)
# Create a retriever from the vector store
retriever_extra_text = vector_store_extra_text.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain_extra_text = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_extra_text
)
# Ask a question
chain_extra_text(
{"question": "What single topic does Andreas know about?"},
return_only_outputs=True
)
⚠️ we need to reset the vector store, retriever, and chain each time the Cypher query is changed.
Another more complete example of customization...
# Create a retrieval query with some extra text on top of the retrieved text
investment_retrieval_query = """
MATCH (node)-[:PART_OF]->(f:Form),
(f)<-[:FILED]-(com:Company),
(com)<-[owns:OWNS_STOCK_IN]-(mgr:Manager)
WITH node, score, mgr, owns, com
ORDER BY owns.shares DESC LIMIT 10
WITH collect (
mgr.managerName +
" owns " + owns.shares +
" shares in " + com.companyName +
" at a value of $" +
apoc.number.format(toInteger(owns.value)) + "."
) AS investment_statements, node, score
RETURN
apoc.text.join(investment_statements, "\n") + "\n" + node.text AS text,
score,
{ source: node.source } as metadata
"""
# Create the LangChain Neo4j vector store
vector_store_with_investment = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=text,
retrieval_query=investment_retrieval_query,
)
# Create a retriever from the vector store
retriever_with_investments = vector_store_with_investment.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
investment_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_with_investments
)
# Ask question
question = "In a single sentence, tell me about Netapp investors."
investment_chain(
{"question": question},
return_only_outputs=True,
)
Writing Cypher with an LLM
One can also use LLM with few shots learning to train an LLM to write Cypher queries and use the result to retrieve the Graph content and generate an answer.
LangChain enable such approach using GraphCypherQAChain
Create a template with few shots as examples
CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Examples: Here are a few examples of generated Cypher statements for particular questions:
# What investment firms are in San Francisco?
MATCH (mgr:Manager)-[:LOCATED_AT]->(mgrAddress:Address)
WHERE mgrAddress.city = 'San Francisco'
RETURN mgr.managerName
# What investment firms are near Santa Clara?
MATCH (address:Address)
WHERE address.city = "Santa Clara"
MATCH (mgr:Manager)-[:LOCATED_AT]->(managerAddress:Address)
WHERE point.distance(address.location,
managerAddress.location) < 10000
RETURN mgr.managerName, mgr.managerAddress
The question is:
{question}"""
Create a CypherQAChain
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"],
template=CYPHER_GENERATION_TEMPLATE
)
cypherChain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=kg,
verbose=True,
cypher_prompt=CYPHER_GENERATION_PROMPT,
)
Query
def prettyCypherChain(question: str) -> str:
response = cypherChain.run(question)
print(textwrap.fill(response, 60))
prettyCypherChain("What investment firms are in Menlo Park?")
prettyCypherChain("What investment firms are near Santa Clara?")
When to use Knowledge Graph over Vector database
(src RAG: Vector Databases vs Knowledge Graphs? by Ahmed Behairy)
Use a Knowledge Graph:
- Structured Data and Relationships: Use graphs when you need to manage and exploit complex relationships between structured data entities. Knowledge graphs are excellent for scenarios where the interconnections between data points are as important as the data points themselves.
- Domain-Specific Applications: For applications requiring deep, domain-specific knowledge, graphs can be particularly useful. They can represent specialized knowledge in fields like medicine, law, or engineering effectively.
- Explainability and Traceability: If your application requires a high degree of explainability (i.e., understanding how a conclusion was reached), graphs offer more transparent reasoning paths.
- Data Integrity and Consistency: Graphs maintain data integrity and are suitable when consistency in data representation is crucial.
Use a Vector Database:
- Unstructured Data: Vector databases are ideal when dealing with large volumes of unstructured data, such as text, images, or audio. They’re particularly effective in capturing the semantic meaning of such data.
- Scalability and Speed: For applications requiring high scalability and fast retrieval from large datasets, vector databases are more suitable. They can quickly fetch relevant information based on vector similarity.
- Flexibility in Data Modeling: If the data lacks a well-defined structure or if you need the flexibility to easily incorporate diverse data types, a vector database can be more appropriate.
- Integration with Machine Learning Models: Vector databases are often used in conjunction with machine learning models, especially those that operate on embeddings or vector representations of data.