It aims to benchmark the performance (latency, throughput, memory & energy) of Large Language Models (LLMs) with different hardwares, backends and optimizations using Optimum-Benchmark and Optimum flavors.
It aims to provide a unified evaluation for LLM safety and help researchers and practitioners better understand the capabilities, limitations, and potential risks of LLMs.
MTEB (Massive Text Embedding Benchmark) Leaderboard
MTEB is a multi-task and multi-language comparison of embedding models. It’s relatively comprehensive - 8 core embedding tasks Bitext mining, classification, clustering, pair classification, reranking, retrieval, semantic text similarity (sts), summarization and open source.
Easy to plugin new models through a very simple API
#evaluation#custom_evals
A lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. It' is the tech behind HF leaderboard.
#evaluation#custom_evals#observability
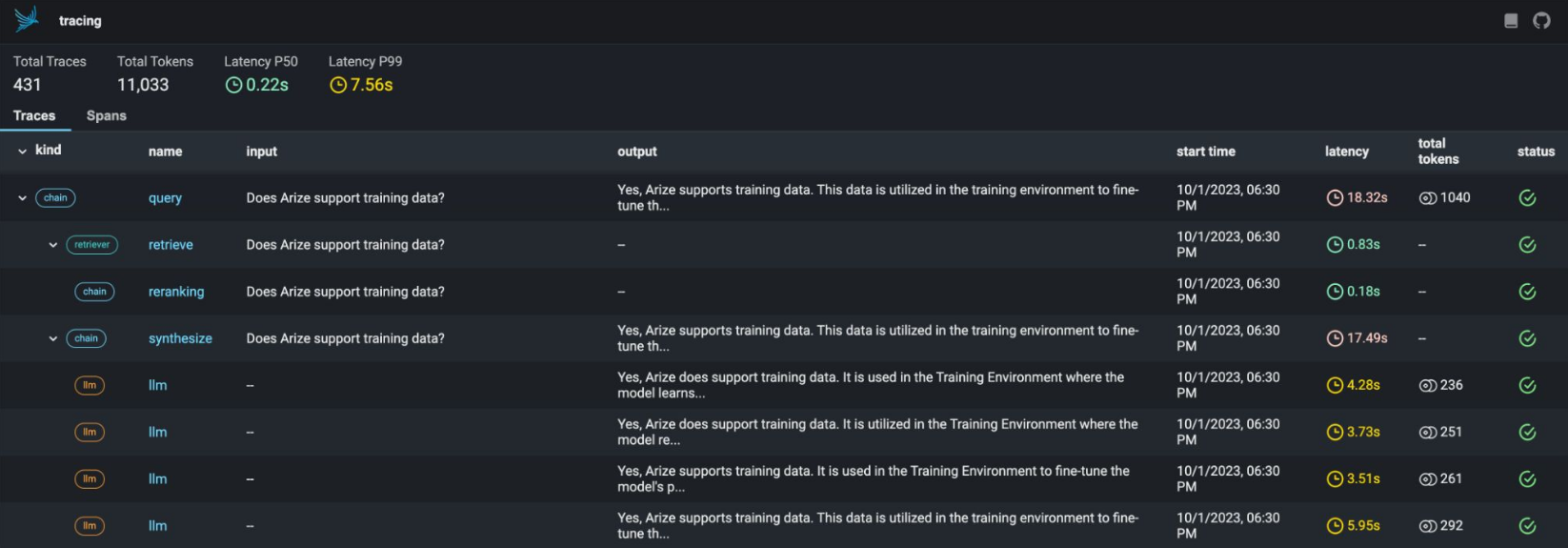
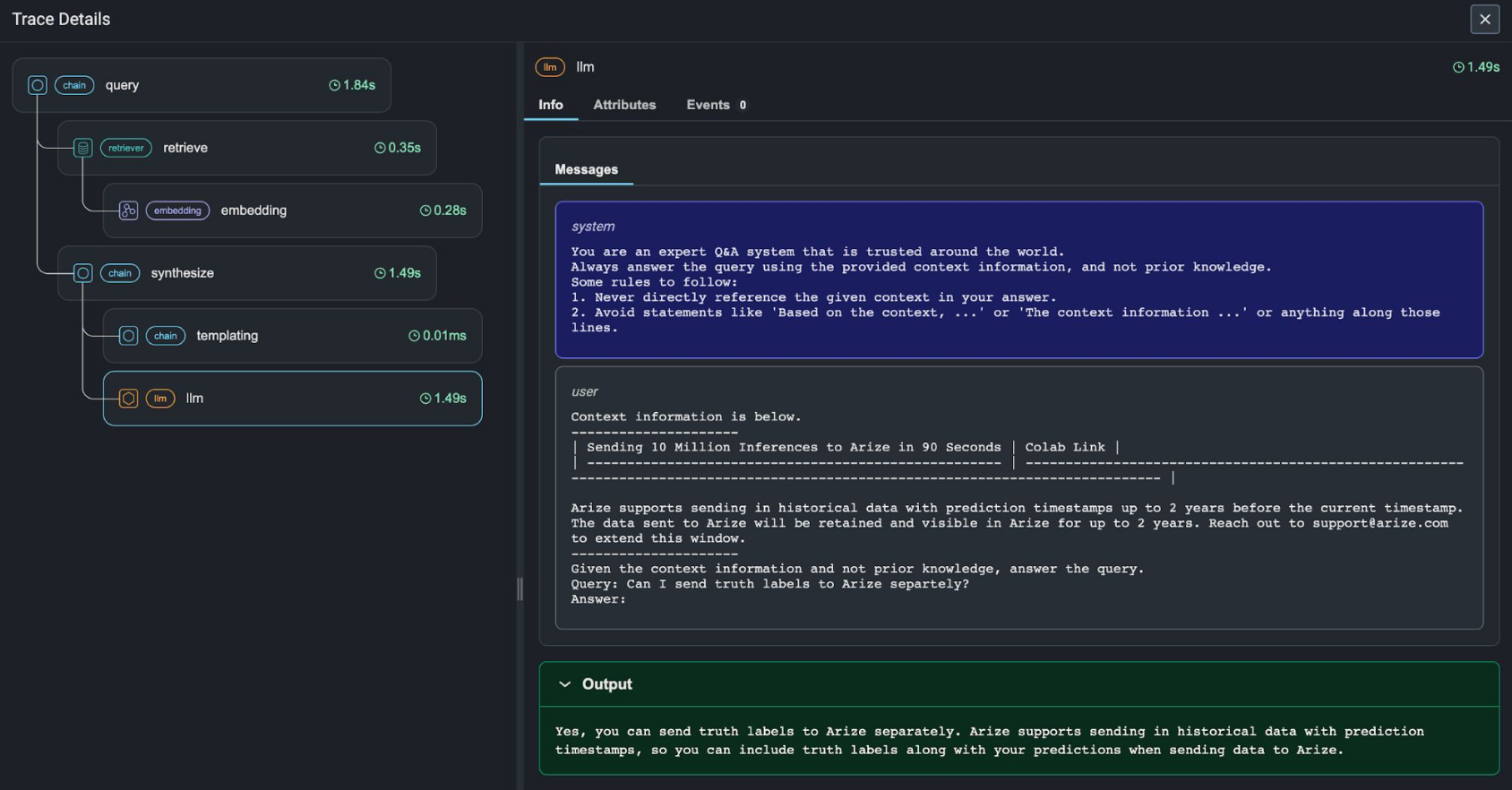
An open-source observability library and platform designed for experimentation, evaluation, and troubleshooting. The toolset is designed to ingest inference data for LLMs, CV, NLP, and tabular datasets as well as LLM traces. It allows AI Engineers and Data Scientists to quickly visualize their data, evaluate performance, track down issues & insights, and easily export to improve.
Has Trace & Span tracking:True Has Trace & Span UI: True (Free in Notebook/Docker/Terminal - Paid in Cloud) Has LLM Evaluation:True Has Pre-defined Evaluations:True Has Custom Evaluations:True
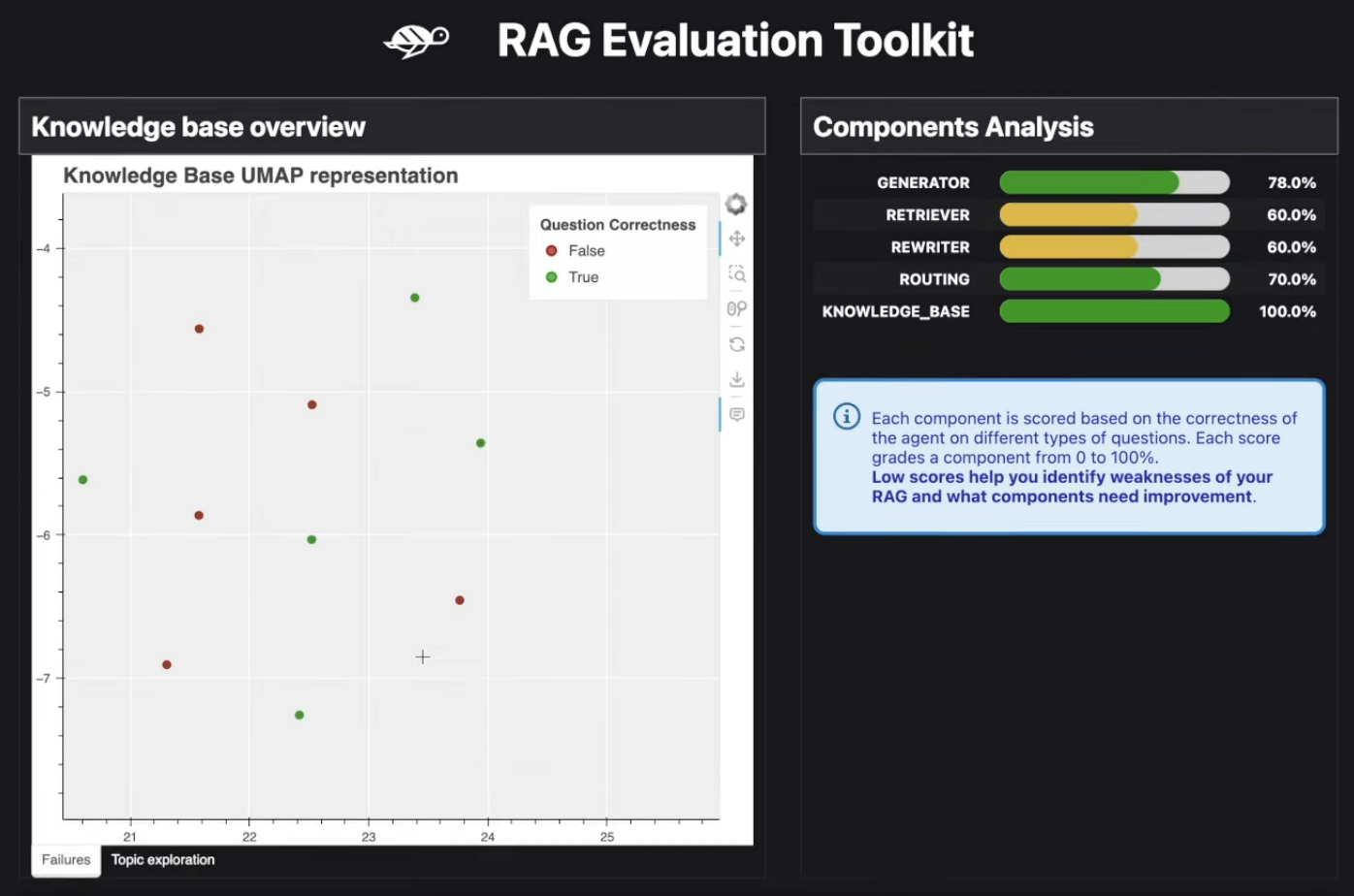
Note: Benchmark both the model and the prompt template. We can see both the dataset embedding AND the queries embedding of the customers as a reduced 2D representation and hence see BAD RESPONSES (what is missing in the database to correctly answer the customers questions).
Here is an example from the Arize Phoenix debugging tool.
DeepEval
#evaluation#custom_evals#RAG
A simple-to-use, open-source LLM evaluation framework. It is similar to Pytest but specialized for unit testing LLM outputs. DeepEval incorporates the latest research to evaluate LLM outputs based on metrics such as hallucination, answer relevancy, RAGAS, etc., which uses LLMs and various other NLP models that runs locally on your machine for evaluation.
Whether your application is implemented via RAG or fine-tuning, LangChain or LlamaIndex, DeepEval has you covered. With it, you can easily determine the optimal hyperparameters to improve your RAG pipeline, prevent prompt drifting, or even transition from OpenAI to hosting your own Llama2 with confidence.
#evaluation#custom_evals#RAG
Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.
#evaluation#custom_evals#RAG
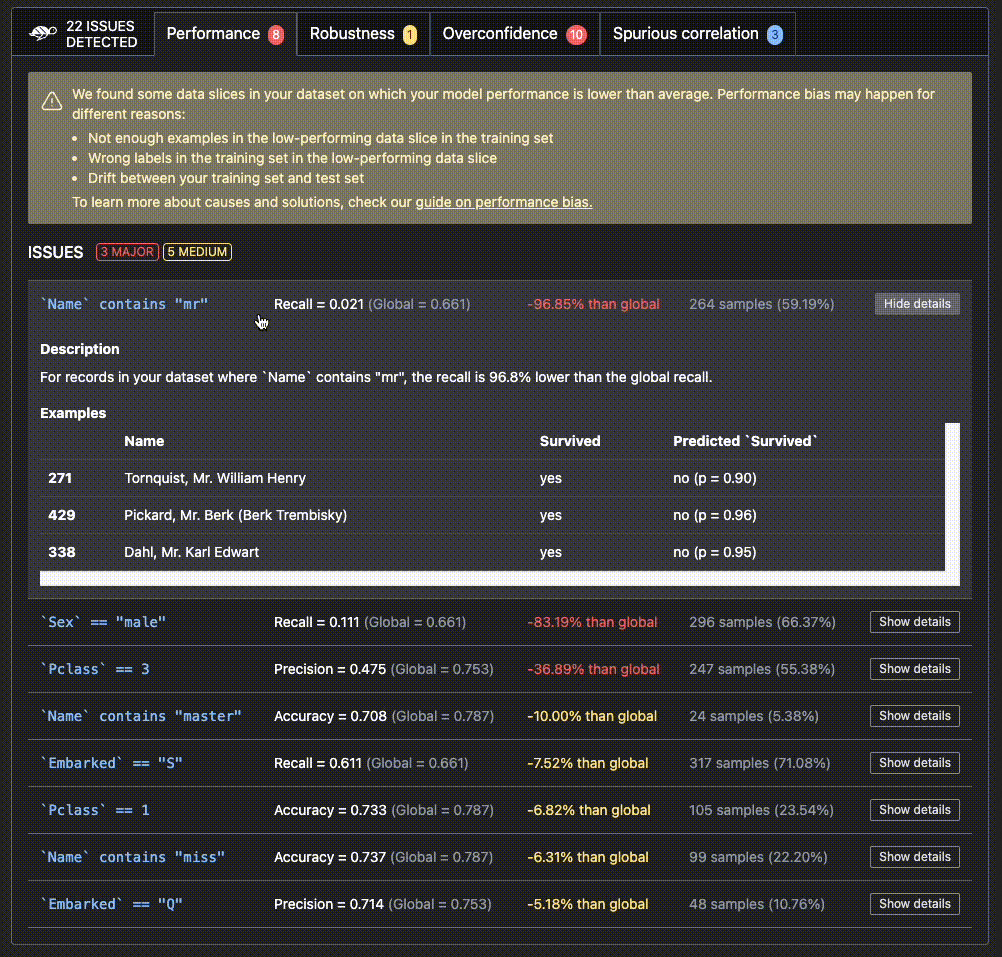
The testing framework dedicated to ML models, from tabular to LLMs. Scan AI models to detect risks of biases, performance issues and errors. Provide PyTest integrations.
Here is an example from the Giskard evaluation tools.
Validate (by Tonic)
#evaluation#custom_evals#RAG#observability
A framework to make easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
#evaluation#custom_evals
This project provides a unified framework to test generative language models on a large number of different evaluation tasks. Over 60 standard academic benchmarks for LLMs, with hundreds of subtasks and variants implemented.
#evaluation#custom_evals#observability
A platform for building production-grade LLM applications. It lets you debug, test, evaluate, and monitor chains and intelligent agents built on any LLM framework and seamlessly integrates with LangChain, the go-to open source framework for building with LLMs.
#evaluation#custom_evals#observability
Evaluate, iterate faster, and select your best LLM app. TruLens is a software tool that helps you to objectively measure the quality and effectiveness of your LLM-based applications using feedback functions. Feedback functions help to programmatically evaluate the quality of inputs, outputs, and intermediate results, so that you can expedite and scale up experiment evaluation. Use it for a wide variety of use cases including question answering, summarization, retrieval-augmented generation, and agent-based applications.
#evaluation#custom_evals
An open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured checks (covering language, code, embedding use-cases), perform root cause analysis on failure cases and give insights on how to resolve them.
#evaluation#custom_evals
Provide a framework for evaluating large language models (LLMs) or systems built using LLMs. We offer an existing registry of evals to test different dimensions of OpenAI models and the ability to write your own custom evals for use cases you care about. You can also use your data to build private evals which represent the common LLMs patterns in your workflow without exposing any of that data publicly.
#evaluation
LlamaIndex is meant to connect your data to your LLM applications. Sometimes, even after diagnosing and fixing bugs by looking at traces, more fine-grained evaluation is required to systematically diagnose issues. LlamaIndex aims to provide those tools to make identifying issues and receiving useful diagnostic signals easy.
The HHEM model is an open source model, for detecting hallucinations in LLMs. It is particularly useful in the context of building retrieval-augmented-generation (RAG) applications where a set of facts is summarized by an LLM, but the model can also be used in other contexts.