References and useful ressources
- https://www.philschmid.de/fine-tune-llms-in-2024-with-trl
- https://cameronrwolfe.substack.com/p/easily-train-a-specialized-llm-peft
What is Fune-tuning
⚠️ TODO: complete it
Re-train LLM on use case or data company.
Fine-tuning vs Adapter-tuning
In standard fine-tuning, the new top-layer and the original weights are co-trained. In contrast, in adapter-tuning, the parameters of the original network are frozen and therefore may be shared by many tasks.
Optimization Techniques
PEFT (parameter efficient training)
⚠️ TODO: complete it
LLaMA-Adapter
⚠️ TODO: complete it
LoRA
⚠️ TODO: complete it
QLoRA
⚠️ TODO: complete it
DoRA
DoRA (Weight-Decomposed Low-Rank Adaptation), is a new, PEFT technique that claims to enhance the learning capacity and training stability of LoRA, while avoiding any additional overhead.
- https://arxiv.org/abs/2402.09353
- https://huggingface.co/docs/peft/v0.10.0/en/developer_guides/lora#weight-decomposed-low-rank-adaptation-dora
- https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_dora-a-new-better-and-faster-lora-dora-activity-7179756964359360512-_Cez?utm_source=share&utm_medium=member_desktop
Insights:
🏅 DoRA consistently outperforms LoRA
🤗 Supported in Hugging Face PEFT
♻️ Trained Adapters can be merged back into the model
📈 +3.4% on Llama 7B and +1.0% on Llama 13B compared to LoRA on common reasoning
🔐 Improved training stability compared to LoRA
❌ In PEFT, DoRA only supports linear layers at the moment
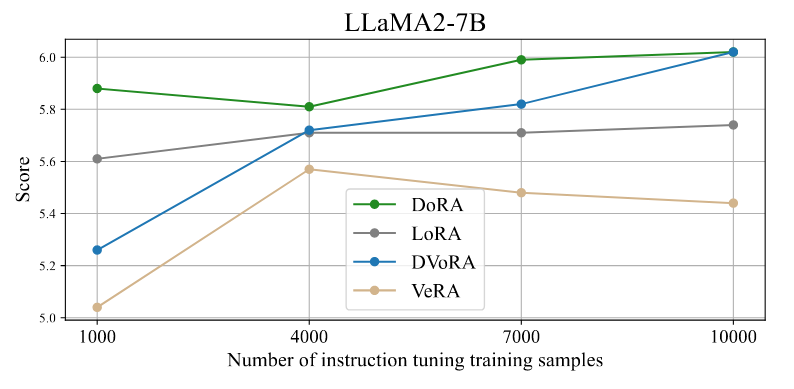
Figure: Performance of fine-tuned LLaMA2-7B on MT-Bench using different numbers of Alpaca training samples.
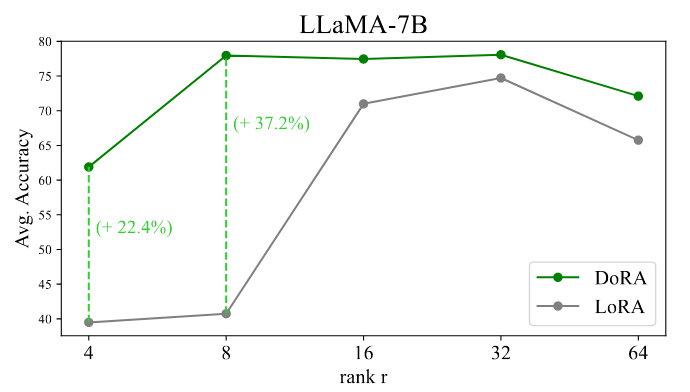
Figure: Average accuracy of LoRA and DoRA for varying ranks for LLaMA-7B on the commonsense reasoning tasks.
GaLore
⚠️ TODO: complete it
https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_galore-is-a-new-memory-efficient-fine-tuning-activity-7177599313294827521-kye2
LoReFT
LoReFT (Low-rank Linear Subspace Representation Fine Tuning) from Stanford University doesn't require any update of model weights at all, while being more efficient and often outperforming other PEFT methods like LoRA (which require only a small subset of weights to be updated).
This is achieved instead by intervening with the intermediate representations output from hidden layers of the model.
- https://arxiv.org/abs/2404.03592
- https://github.com/stanfordnlp/pyreft
- https://www.linkedin.com/posts/andrew-iain-jardine_llms-activity-7182723145651433472-i8Fx
Insights:
🔹 LoReFT is 10-50x more efficient that other PEFT methods
🔹 Improves performance on instruction following vs LoRa or full-tuning
🔹 Comparable or better performance for reasoning vs LoRa
🔹 Potentially could be used in conjunction with weight altering PEFT methods
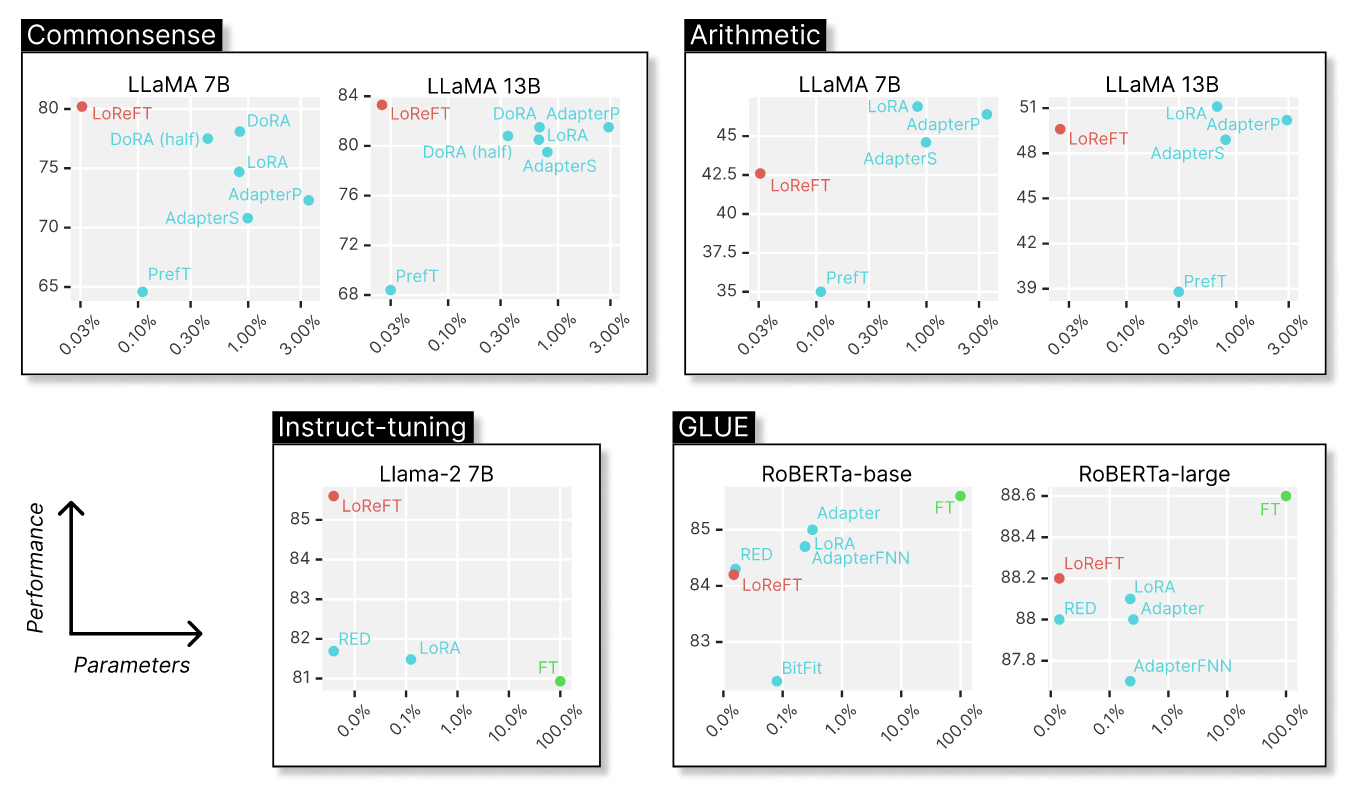
Training process:
1️⃣ Weights of the base LLM are frozen
2️⃣ Specific layers of the model are selected for intervention
3️⃣ Projection matrix for each layer is trained to edit layer output representations
4️⃣ At inference the projection matrix intervenes to change the output
5️⃣ Altered hidden states passed through model layers changing generation
6️⃣ Evaluated on reasoning, instruction and NLU benchmarks vs PEFT methods
Handily the team has introduced a new library Pyreft to handle this process
Preference Alignment algorithms
Model Quantization
⚠️ TODO: complete it