References and useful ressources
- https://courses.arize.com/courses/llm-evaluations
- https://arize.com/blog-course/llm-evaluation-the-definitive-guide/
- https://arize.com/blog-course/numeric-evals-for-llm-as-a-judge/
- https://arize.com/blog-course/the-needle-in-a-haystack-test-evaluating-the-performance-of-llm-rag-systems/
- https://docs.arize.com/phoenix/tracing/use-cases-tracing/rag-evaluation
LLMs' problems
- Hallucinations
- Misinformation + incorrect answer
- Made up answers
- Contrived references
- Inaccurate Responses
- Answers that are obviously wrong
- Wrong answers delivered in very confident sounding prose
- Inappropriate Responses
- Toxic answers
- Biased answers
Possible causes
- Bad model
- A model whose characteristics doesn't match the use case has been selected
- The base model was poorly evaluated
- Bad Retrieval
- Inappropriate data storage
- Wrong retrieval function or method (Similarity function, Hybrid search, ...)
- Wrong data preparation (splitting, indexing)
- Wrong RAG strategy (CoT, CoD, CoN, CCoT, HyDE...)
- No re-ranking or bad re-ranking
- No filtering/pruning after re-ranking (if k=10 then keep 4 or 5 after re-ranking)
- Not placing the more relevant retrieved chunks at the top or bottom of context (see Lost in the Middle paper)
- Not using metadatas to help narrowing the chunks (and speed up the process)
- Dataset mismatch user questions (the dataset doesn't contain the answer)
- Bad prompt
- Template misses the mark
- Prompt in one language and user input in another
- Not asking the model to say "I don't know" when the context doesn't contain the answer
- No security
- No Guardrail to ensure the input is allowed
- No protection against prompt injection
- No fine-tuning
- Try to solve model behaviour with prompting rather than fine-tuning (but one should always start with prompt engineering)
What do we need to evaluate ?
Evaluation must cover different aspects of use of the LLM (both by tasks and by semantic category and from NLP metrics to production metrics to end-to-end system metrics).
- Embedding Model : is the embedding correctly separating the concepts of the use-case?
- LLM Model : is the model performing well generally?
- LLM System - RAG Retrieval : is the retrieved data appropriate? are the provided links/src OK?
- LLM System - RAG Generation : is the generated answer using the provided context?
- LLM End-to-End : overall are the selected Model and System (Q&A, Summarization, Code, etc.) answering the user questions?
Embedding Model Evaluations
There are standard traditional information retrieval methods to evaluate embeddings such as Recall@K, Precision@K, NDCG@K that are easy to implement.
Another critical part of embedding evaluation is the performance/operations evaluation: Cost, latency, throughput. Because in many cases, embeddings must be generated for every item on every update or for every query with latency limits...
But there also exists more complex evaluation tools such as the MTEB which is a good example of a more complete embedding evaluation tasks. This board also shows that there are no clear winners across all tasks. So we need to select or train one depending on the current use-case.
LLM Model Evaluations
In this case we are evaluating the overall performance of the foundational models. Other said, we compare several foundational models (or versions), just like with regular Machine Learning evaluations. So the very same dataset(s) are used on each model to assess a given list of tasks.
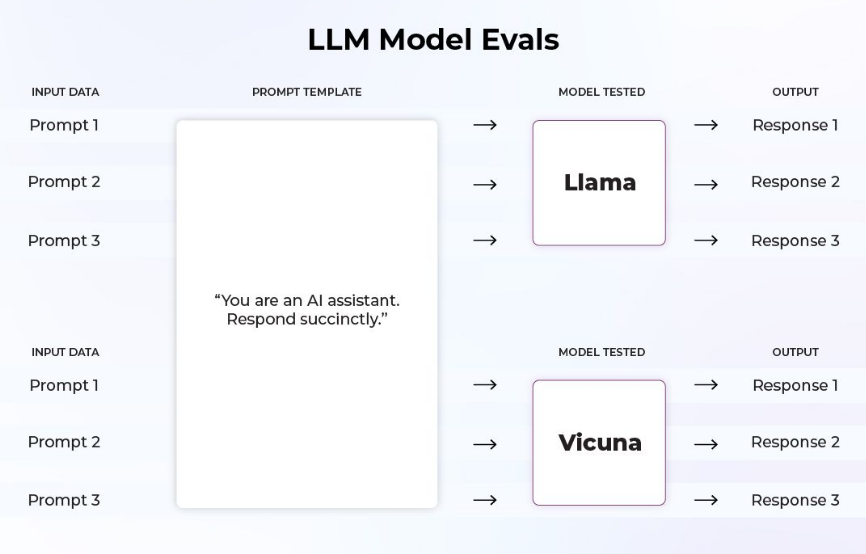
Typically, early stage / pre-training is evaluated on standard NLP metrics such as SQuaD 2.0, SNLI, GLUE, BLUE score, ROUGE score etc. that are good to measure standard NLP tasks.
LLM System Evaluations
In this case, we are evaluating how well the inputs can determine the outputs. We observe the various components in the LLM system that we have control over (including fine-tuning or adapter-tuning), to see why we ends up with a good or a wrong answer in the ouput. So the very same dataset is used on each LLM system to assess a given list of tasks and compare them.
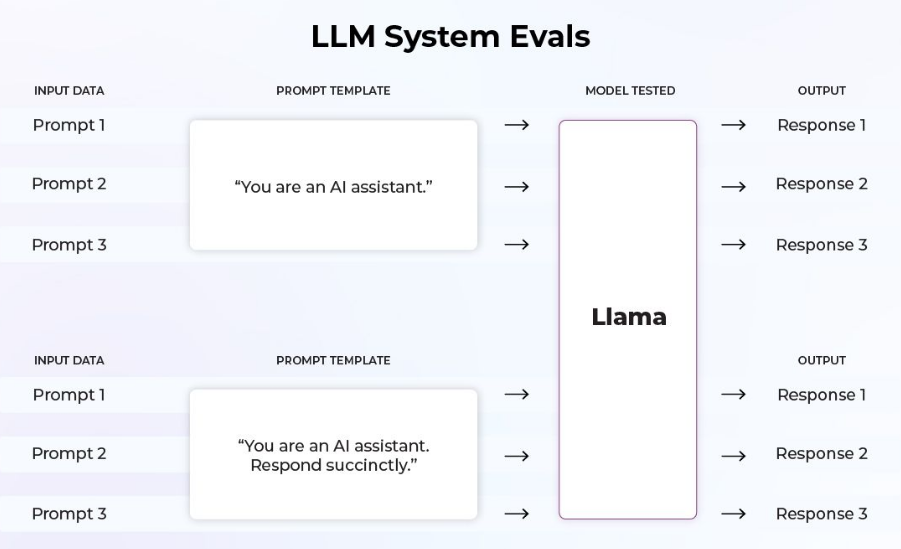
Evaluation Metrics
- LLM assisted evaluation
- Different templates and different models for different tasks (Relevance, Hallucinations, Toxicity, Honesty ,Question answering eval, Summarization eval, Translation eval, Code generation eval, Ref Link eval ... )
- User-provided feedback
- Thumbs up / thumbs down
- Accept or reject response
- ...
- Task based metrics (and benchmarks)
- Perplexity - evaluate how well a probability distribution of a test sample is matching with the corresponding LLM prediction.
- ROUGE score - evaluate summarization or translation,
- BLUE score - evaluate translation,
- METEOR score - evaluate translation,
- CIDEr score - evaluate image captioning,
- HellaSwag benchmark – evaluate sentence completion,
- TruthfulQA benchmark - evaluate truthfulness,
- MMLU benchmark - evaluate how well the LLM can multitask,
- ...
- Multi-metric evaluation
- FLASK benchmark - defines four primary abilities which are divided into 12 fine-grained skills to evaluate the performance of language models comprehensively.
- HELM benchmark - adopts a top-down approach explicitly specifying the scenarios and metrics to be evaluated and working through the underlying structure.
- LM Evaluation Harness benchmark - a unified framework used by the
Hugging Face LLM Leaderboard, to test generative language models on a large number of different evaluation tasks. - ...
- RAG / Ranking / Recommendation metrics
- Precision@K - measures the percentage of relevant documents amongst the top K retrieved documents (without taking into account the position of the item in the list),
- NDCG - compare rankings to an ideal order where all relevant items are at the top,
- Hit rate - measures the share of users that get at least one relevant recommendation (it can be a binary True/False if considering one query, or a ratio if considering K queries),
- MRR - helps understand the average position of the first relevant item across all user lists,
- ...
⚠️ Recommendation: use Confusion Matrices with categorical variables rather than just scores because scores are way harder to interpret and hence to dig for the problem.
Evaluation datasets
There exist a lot of evaluation datasets (see 05 Generative AI/LLM/Tools/_Tools) ready to assess Common Sense, Math & Problem Solving, Q&A, Summarization, Code generation ... and they are always a good starting point or a good complement.
But nothing beats a Golden Dataset built with the project's data and specifically tailored for a given use case.
Ideally, this dataset should be created/curated by Humans with enough expertise in the domain covered by the data, but in practice, it's hard to gather such a team at a reasonable price... So, an alternative is to rely on very good LLMs (such as GTP-4 or Claude-3 at the time of writing) to help generate interesting and useful examples.
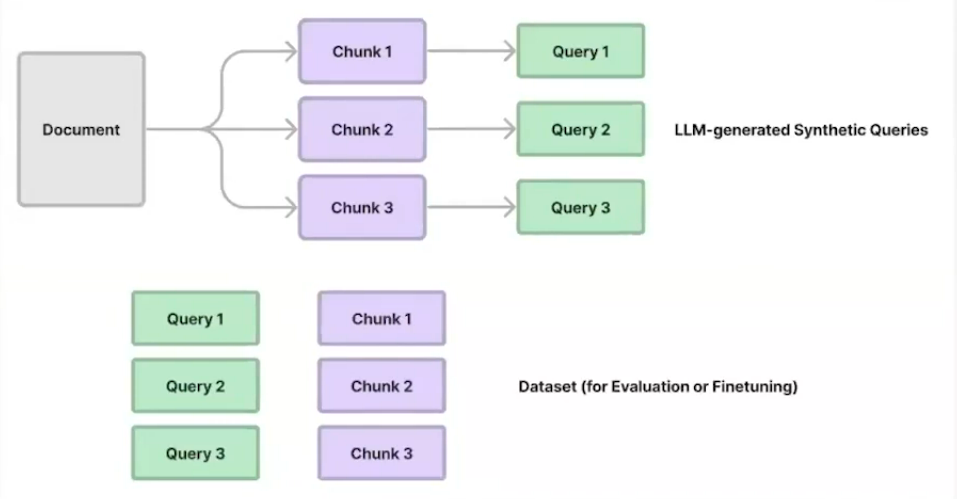
Synthetic Data Generation for Retrieval Evaluations
- Parse / chunk-up text corpus.
- Prompt an LLM (GTP-4) to generate questions from each chunk (or for subset of chunks).
- If the dataset aims to be a Golden Dataset, carefully review the pairs.
- Each pair (question, chunk) can be used for Evaluation or Fine-tuning.
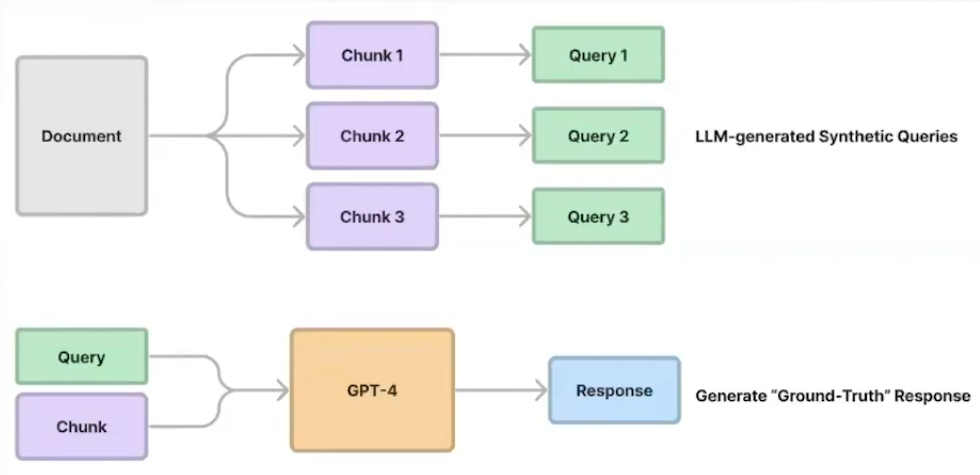
Synthetic Data Generation for End-to-End Evaluations
- Parse / chunk-up text corpus.
- Prompt an LLM (GTP-4) to generate questions from each chunk (or for subset of chunks).
- Run (question, context) pairs through an LLM (GPT-4) to get a ground-truth response.
- If the dataset aims to be a Golden Dataset, carefully review the pairs.
- Each pair (question, ground-truth-response) can be used for Evaluation or Fine-tuning.
Good practices
- Benchmark using a Golden Dataset.
- Use cross-validation on the Golden Dataset to avoid overfitting (hold-out, k-fold ...).
- Evaluate the LLM based on the appropriate task(s) (not a generic metric unrelated to the use-case).
- Carefully define the LLM Evaluation Templates (or use libraries with built-in prompt templates).
- Run End-to-end evaluation first, and if there is a problem run other evals.
- Queries and document change over time, so the evaluations must reflect these changes to avoid Concept drift or Data drift.
- Select the foundation model using relevant metrics for the use case.
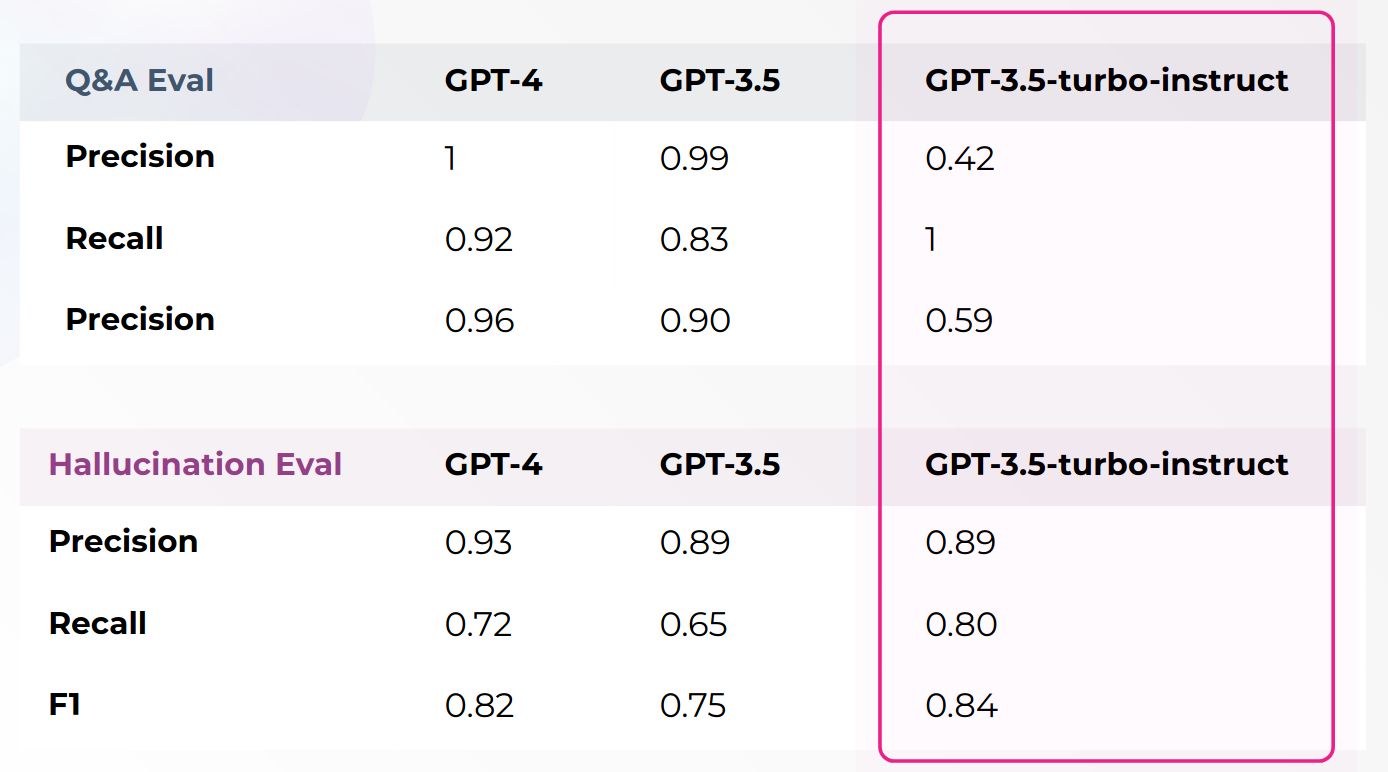
In the above table, we can see that even if GPT-3.5-turbo-instruct is not a good model for Q&A, it might be a good (and cheap) option for Pure completion (such as playing a chess game, generating code, generating poems etc...)
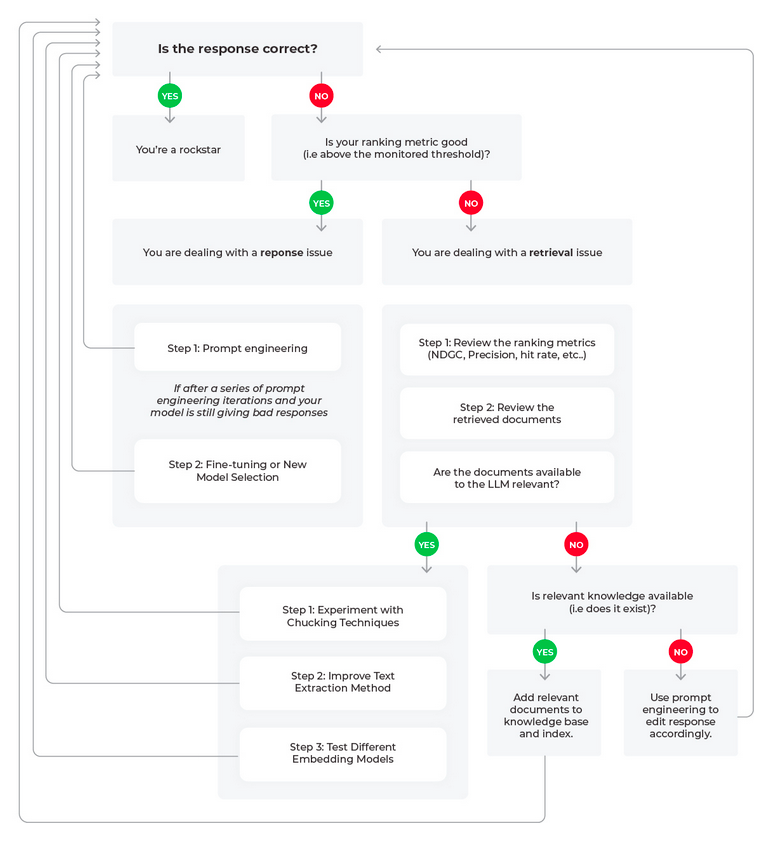
How to fix Hallucinations / Responses quality
- Improve retrieval / ranking of relevant documents
- Improve chunking strategy & document quality
- Improve prompt (prompt engineering)
Notebooks from Arize Phoenix
Lab 1
Evaluating Hallucinations
- Evaluate the performance of an LLM-assisted approach to detecting hallucinations.
- Provide an experimental framework for users to iterate and improve on the default classification template.


Lab 2
Evaluating Toxicity
- Evaluate the performance of an LLM-assisted toxic detection.
- Provide an experimental framework for users to iterate and improve on the default classification template.
Lab 3
Evaluating Relevance of Retrieved Documents
- Evaluate the performance of an LLM-assisted approach to relevance classification against information retrieval datasets with ground-truth relevance labels,
- Provide an experimental framework for users to iterate and improve on the default classification template.
Lab 4
Evaluating RAG with Phoenix's LLM Evals
- In this lab we will look into building a RAG pipeline and evaluating it with Phoenix Evals.
Lab 5
Evaluating RAG with Giskard-AI
- In this lab we will look into building a RAG pipeline using Langchain and evaluating it with Giskard-AI.
- Batch evaluation
- pyTest and iPyTest integration

Lab 6
Evaluating Question-Answering
- Evaluate the performance of an LLM-assisted approach to detecting issues with Q&A systems on retrieved context data.
- Provide an experimental framework for users to iterate and improve on the default classification template.
Lab 7
Evaluating Summarization
- Evaluate the performance of an LLM-assisted approach to evaluating summarization quality,
- Provide an experimental framework for users to iterate and improve on the default classification template.
Lab 8
Evaluating Code Readability
- Evaluate the performance of an LLM-assisted approach to classifying generated code as readable or unreadable using datasets with ground-truth labels
- Provide an experimental framework for users to iterate and improve on the default classification template.
Lab 9
Evaluating and Improving a LlamaIndex Search and Retrieval Application
Metrics Ensembling
⚠️ TODO: write this section
LLM Model Evaluation libraries, metrics & leaderbords
Libraries
- OpenAI Eval : https://github.com/openai/evals
- LightEval (by Hugging-Face) : https://huggingface.co/lighteval
Metrics
Leaderboards
- Open LLM Leaderboard : https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- LMSys (Elo rating) : https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Basic steps to improve the answers
- Zero-shot prompts
- Few-shot prompts
- Retrieval-Augmented few-shot prompts
- Fine-tuning
- Custom model
