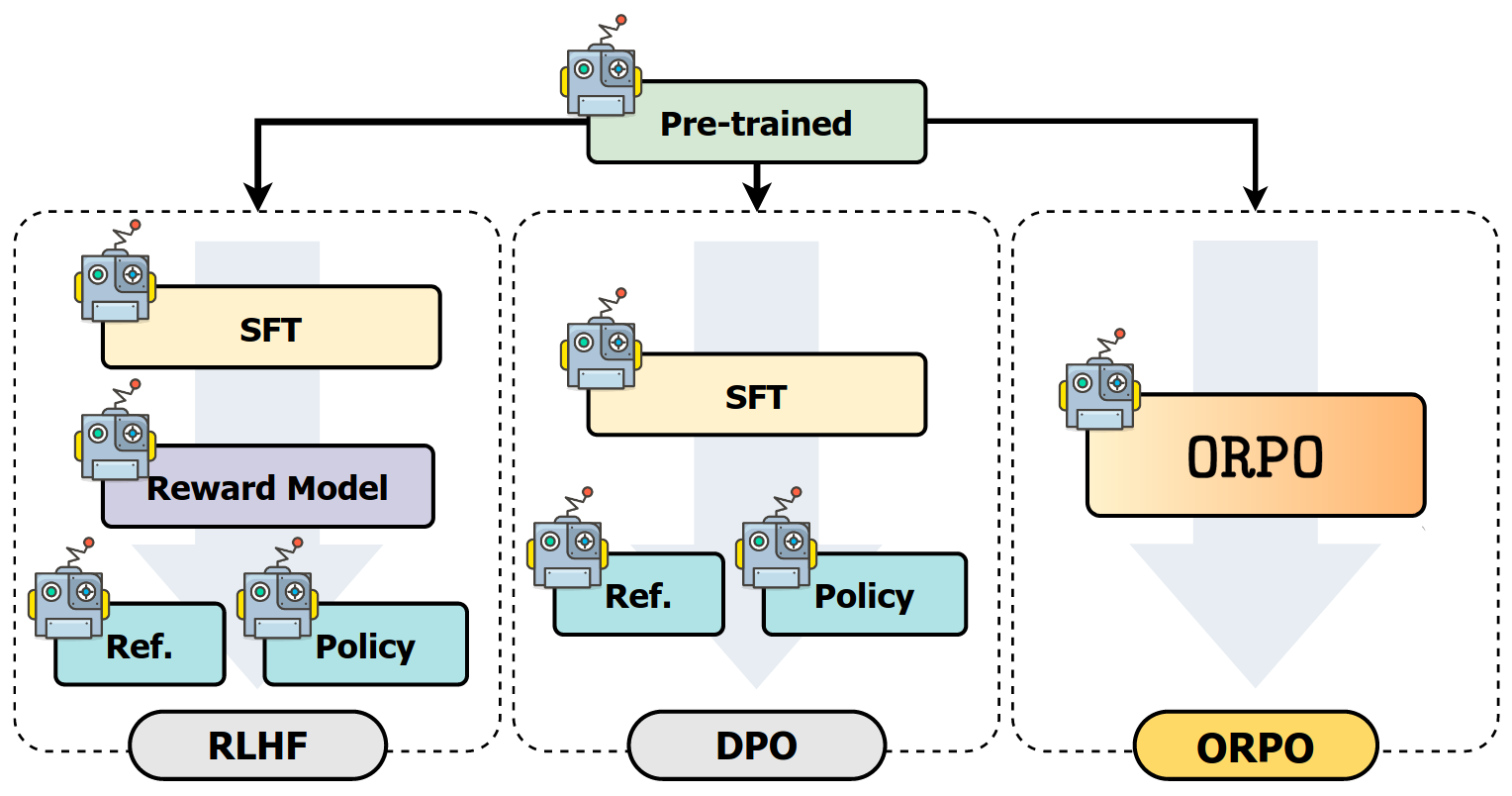
RLHF (with PPO)
RLHF (Reinforcement learning from human feedback) with PPO (Proximal Policy Optimization) proposes ...
⚠️ TODO
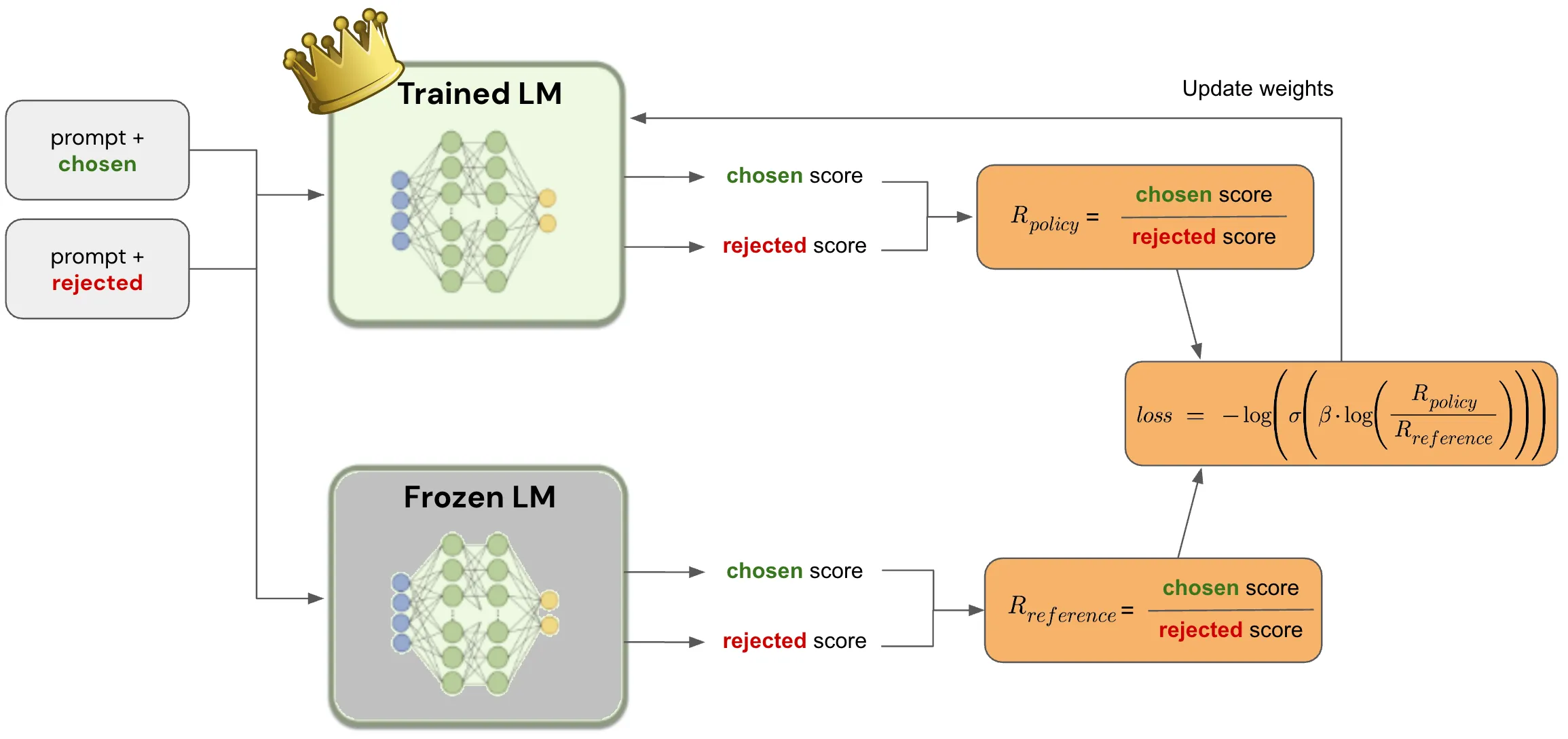
DPO
With the introduction of DPO (Direct Preference Optimization), aligning LLMs has become easier, more efficient, and accessible to everyone! 🌟
In DPO, there is no reinforcement learning, and the model is directly optimized using the preference data.
⚠️ TODO : complete it
- https://arxiv.org/abs/2305.18290
- https://www.philschmid.de/dpo-align-llms-in-2024-with-trl
- https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_deeplearning-machinelearning-science-activity-7071038436542963713-iNO3
- https://medium.com/@joaolages/direct-preference-optimization-dpo-622fc1f18707
Insights:
1️⃣ DPO claims to offer a stable alternative to RL for fine-tuning language models. 💪
2️⃣ solves the challenge of aligning LLMs with human feedback using a single stage of policy training. 🎯
3️⃣ No need for a Reward Model ✨
4️⃣ DPO surpasses RL in controlling sentiment and improving response quality in summarization and single-turn dialogue tasks. 🎉
OAIF
OAIF (Online AI feedback) utilizes an LLM to provide online feedback, demonstrating superior performance over offline DPO and RLHF methods through human evaluation. 🤔
Online, in RLHF and RLAIF refers to the training data being acquired interactively and resampled from the LLM, rather than using fixed ones (offline). 👨🏫
- https://arxiv.org/abs/2402.04792
- https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_is-online-ai-feedback-oaif-the-next-iteration-activity-7161736904747511810-tnKa
Insights:
🎯 Annotator could be seen as a Reward Model
🔍 Quality of Annotator LLM is crucial for the result of online DPO
💡 Annotator LLM can be steered through prompting, e.g. “helpful and very short” or “always include code”
⚖️ Policy(trainable LLM) and Annotator LLM are different models
🔄 Offline DPO can overfit (with limited data?)
📊 Use OAIF if there is not enough offline data
⏱️ Behavior of LLM visibly changes after 2,000 steps or 256,000 samples.
🌐 Online DPO could be used to make the model more sensible to system prompts
🗨️ Could be used for multi-turn conversations when generating User prompts by LLM
Training process:
0️⃣ Select a fine-tuned LLM, which could be SFT or DPO, and prepare a dataset of prompts
1️⃣ Generate two responses for a batch of prompts
2️⃣ Use LLM as an Annotator to obtain “online” feedback scores response in both possible orders to avoid bias
3️⃣ Update the model using, e.g., DPO
Repeat 1️⃣ - 3️⃣
KTO
KTO (Kahneman & Tversky's Optimization) tries to simplify the optimization by using binary feedback on individual outputs. 👍🏻👎🏻 This is less complex and can be directly used on real-world data. 🌍
Insights:
👩🔬 Contextual AI ran 56 experiments using DPO, KTO, and PPO (RLHF)
🚀 KTO matches the performance of DPO & PPO
🦙 KTO showed better performance on bigger models (llama 1)
💡 Simplifies data requirements compared to DPO & RLHF
⚖️ Need a balanced binarized dataset (50% good 50% bad examples)
Training process:
1️⃣ Collect binary feedback data
2️⃣ Create a balanced (50/50) dataset out of triplets (prompt, response, feedback)
3️⃣ Apply KTO to a fine-tuned LLM using the dataset (2️⃣)
4️⃣ Evaluate outputs from the KTO model vs the old model using LLM as a judge or humans.
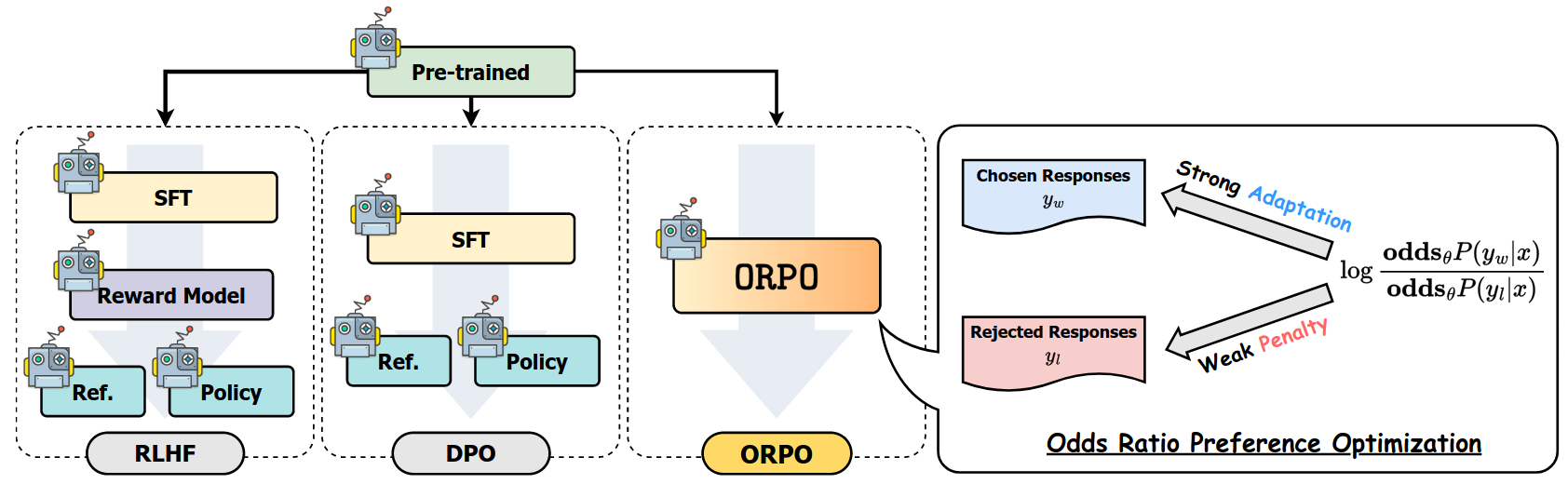
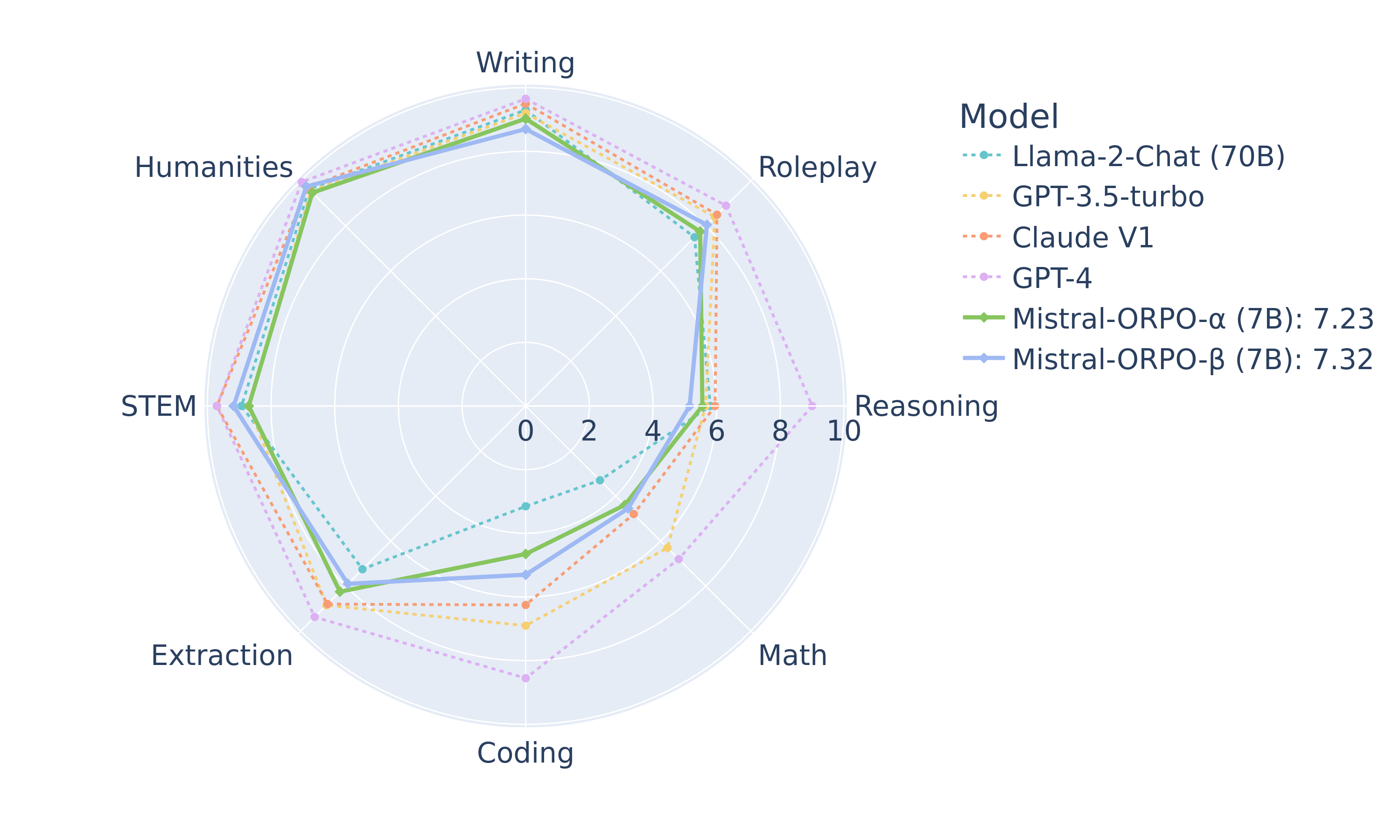
ORPO
ORPO (Odds Ratio Preference Optimization) proposes a method to train LLMs by combining SFT and Alignment into a new objective (loss function), achieving state of the art results.
- https://arxiv.org/abs/2403.07691
- https://github.com/xfactlab/orpo
- https://huggingface.co/kaist-ai/mistral-orpo-beta
- https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_can-orpo-redefine-how-we-train-and-align-activity-7174690924403249152-c-X8
Demo notebook:
- Finetuning a base model with ORPO

Insights:
🧠 Reference model-free → memory friendly
🔄 Replaces SFT+DPO/PPO with 1 single method (ORPO)
🏆 ORPO Outperforms SFT, SFT+DPO on PHI-2, Llama 2, and Mistral
Training process:
1️⃣ Create a pairwise preference dataset (chosen/rejected), e.g. Argilla UltraFeedback.
2️⃣ Make sure the dataset doesn’t contain instances where the chosen and rejected responses are the same, or one is empty.
3️⃣ Select a pre-trained LLM (e.g., Llama-2, Mistral)
4️⃣ Train the Base model with ORPO objective on preference dataset
⚠️ No extra SFT step, directly applied to base model 🔥
PERL
PERL (Parameter Efficient Reinforcement Learning) looks to address the computational cost of RL by introducing LoRA for reward and policy model training.
⚠️ TODO: complete it
- https://arxiv.org/abs/2403.10704
- https://www.linkedin.com/posts/andrew-iain-jardine_llm-opensource-activity-7177681446776578049-GORG
Insights:
🔹Performance equivalent to full tuning, sometimes better
🔹Requires updating as few as 0.1% parameters
🔹Reduces memory 50% and training time 90% for RM training
🔹Reduces memory 20% and training time 10% for RL Policy training
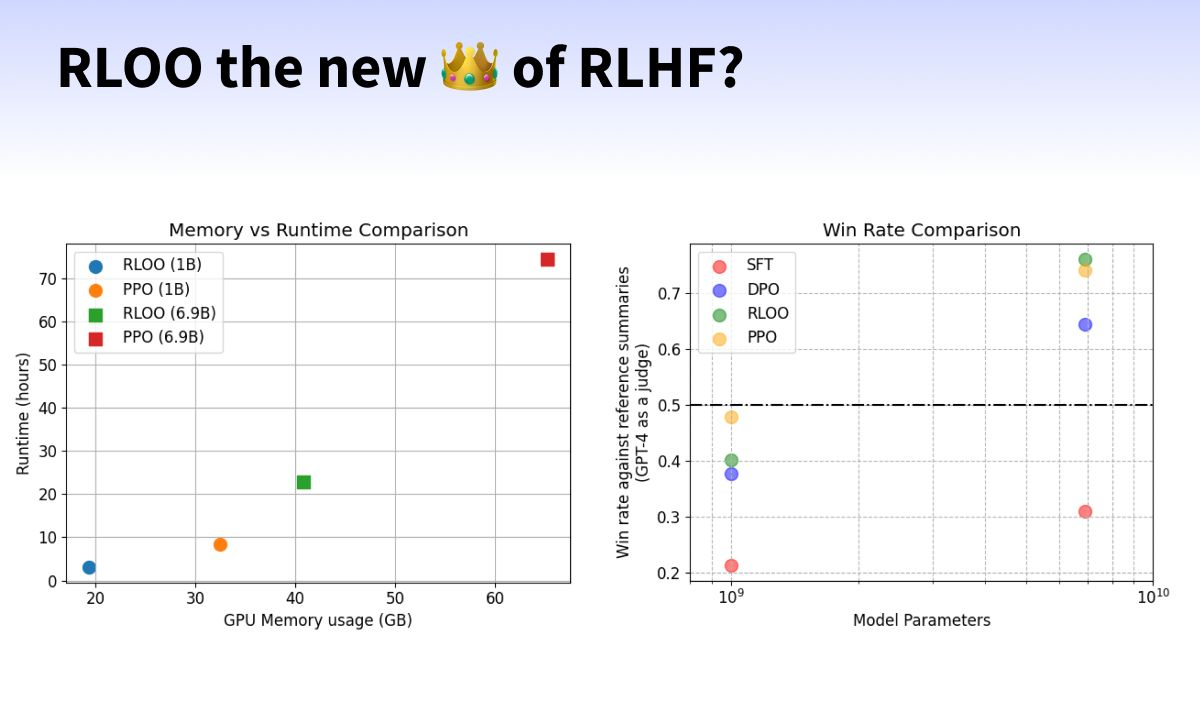
RLOO
RLOO simplifies the RLHF training process by treating the entire model completion as a single action and using REINFORCE. It does not require a value model; it just generates more sequences.
This reduces memory requirements, making it easier to avoid out-of-memory errors and allowing for larger batch sizes.
RLOO extends REINFORCE by incorporating a leave-one-out mechanism, which involves:
1️⃣ Sampling Multiple Trajectories: Generating multiple samples (k) for each prompt.
2️⃣ Calculating Leave-One-Out Rewards: For each sample, the reward is calculated by considering the average reward of all other samples, reducing the variance of the estimated gradients.
- https://arxiv.org/pdf/2402.14740
- https://www.linkedin.com/posts/philipp-schmid-a6a2bb196_rloo-the-new-of-rlhf-rloo-simplifies-activity-7206678738372050944-kQV_/?utm_source=share&utm_medium=member_android
Insights:
💡 RLOO requires ~50-70% less memory and 2-3x runs faster than PPO
📦 It only requires three model copies in memory versus four in PPO.
🎛️ RLOO is less sensitive to hyperparameter tuning than PPO.
🏆 RLOO (k=4) achieves 62.2% win-rate on Anthropic-HH dataset, outperforming RAFT (59.3%), PPO (56.7%), and DPO (50.0%).
📈 Higher k in RLOO leads to better performance (61.9% at k=4 vs 61.3% at k=2).
🤗 Available in Hugging Face TRL