References and useful ressources
Methods
- Extractive - directly copies salient sentences from the source document and combine them as the output.
- Abstractive - imitates a human that comprehends a source document and writes a summary output based on the salient concepts of the source document.
- Hybrid - attempts to combine the best of both approaches by rewriting summary based on a subset of salient content extracted from the source document.
We don't handle short and long document summary the same way. As data grows, the essence becomes harder to capture. Making sure the summary is a good representation of the larger text (Books, Large number of small texts merged as one document, ...) can be challenging.
Algorithms
Map Reduce
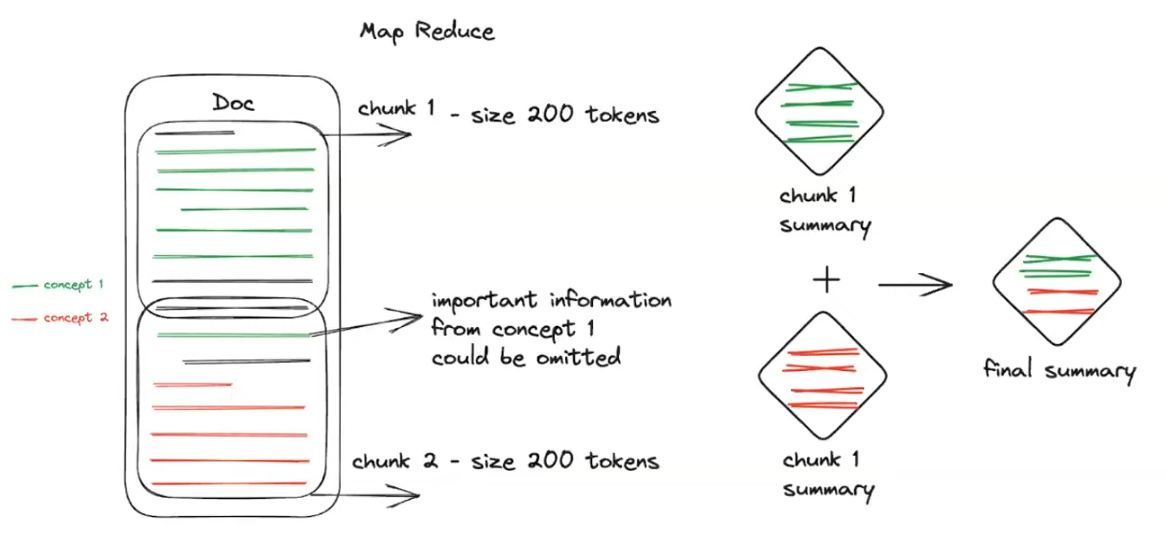
- split into chunks of a given size
- summarize each chunk
- merge several chunk summaries (depending on the setting)
- summarize the new "super-chunk"
- apply recursively until there is one “root” node
⚠️ Splitting the text into chunks with no regard for the logical and structural flow of the text can cause issues in summarization, because some key points may be longer than others and hence important information may be lost. However, the nature of this approach allows to apply parallelisation to speed up the process.
Refine
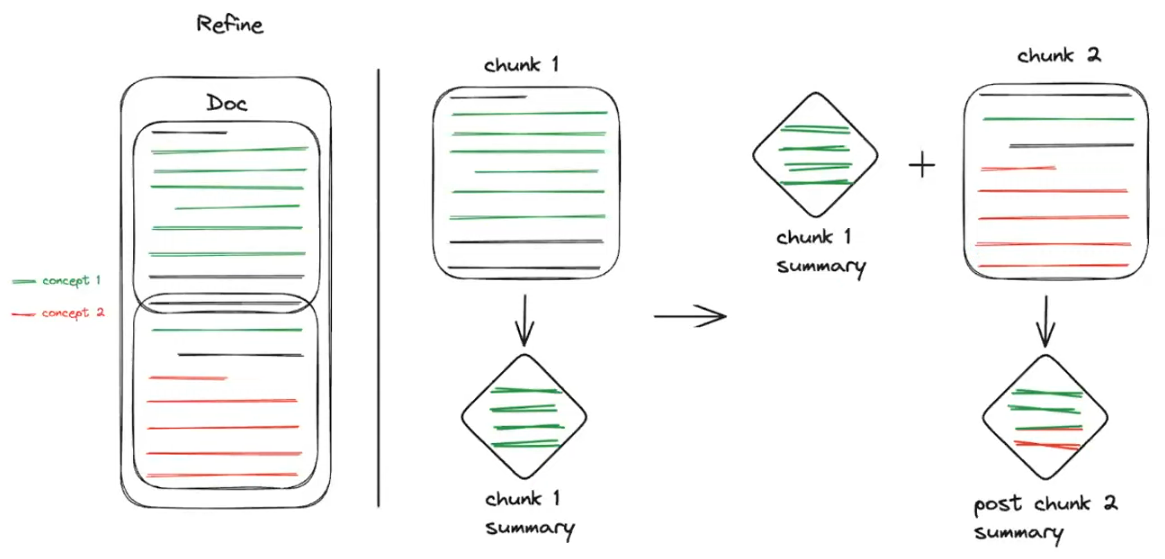
- split into chunks (not necessarily of the same size)
- summarize the 1st non-summarized chunk
- merge the summary with the next non-summarized chunk
- summarize the new "super-chunk"
- apply sequentially until the final chunk so we end-up with one “root” node
⚠️ The sequential nature of this approach means that it cannot be parallelized and takes far longer than recursive methods. Also, research suggests that the meaning from the initial parts may be over-represented in the final summary.
Approaches
Summarizing long docs (with connecting ideas)
- split into chunks (not necessarily of the same size)
- get Titles and Summaries for each chunk
- get embeddings for chunks
- Topic Modelling: group similar embedding together
- Topic Modelling: detect Topics from the chunks
- get Titles and Summaries for each Topic using their associated chunks
- optionally apply Map Reduce or Refine methods on the Topic summaries so we end-up with one "root" node
This approach will produce a hierarchical summarization with an accurate semantic capture retaining the essential information.
⚠️
- Don't arbitrarily chunk based on length
- Use advanced methods such as Topic Modelling to identify the main topics, then summarize each topic
- The part of each topic in the final summary isn't necessarily proportional to the size of each topic in the original document (something very important could be a very short part of the document)
- summarizing long docs with connecting ideas is different than summarizing long docs composed of several small unconnected docs (such as reviews, posts, descriptions etc.)
Summarizing large number of small docs (reviews, posts, product descriptions, new articles)
This kind of documents doesn't have a hierarchy or a structural flow. So we need to carefully select define what we want to capture as the "essence" of the documents and what strategy to apply tho reach this goal.
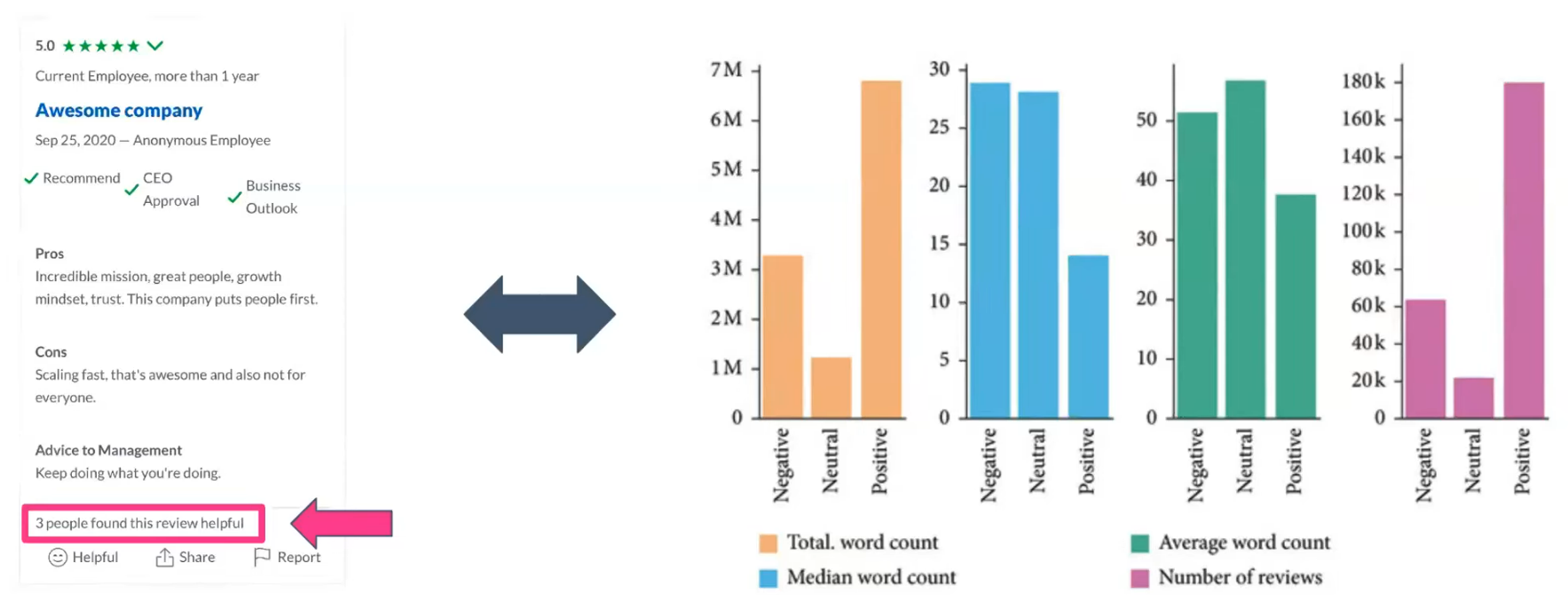
- Sample by using highly weighted texts (based on indicators such as "X people found that review helpful" or "X people shared this article") or taking a stata amongst texts (e.g. good, bad, neutral...)
- then apply Map Reduce or Refine...
Summarizing small number of docs when it fits in the context window
If the text fits into the context window, the best strategy might be to send all the chunks at once. No need for fancy approaches, unless we want to remove titles, sub-titles etc. or cut the costs.
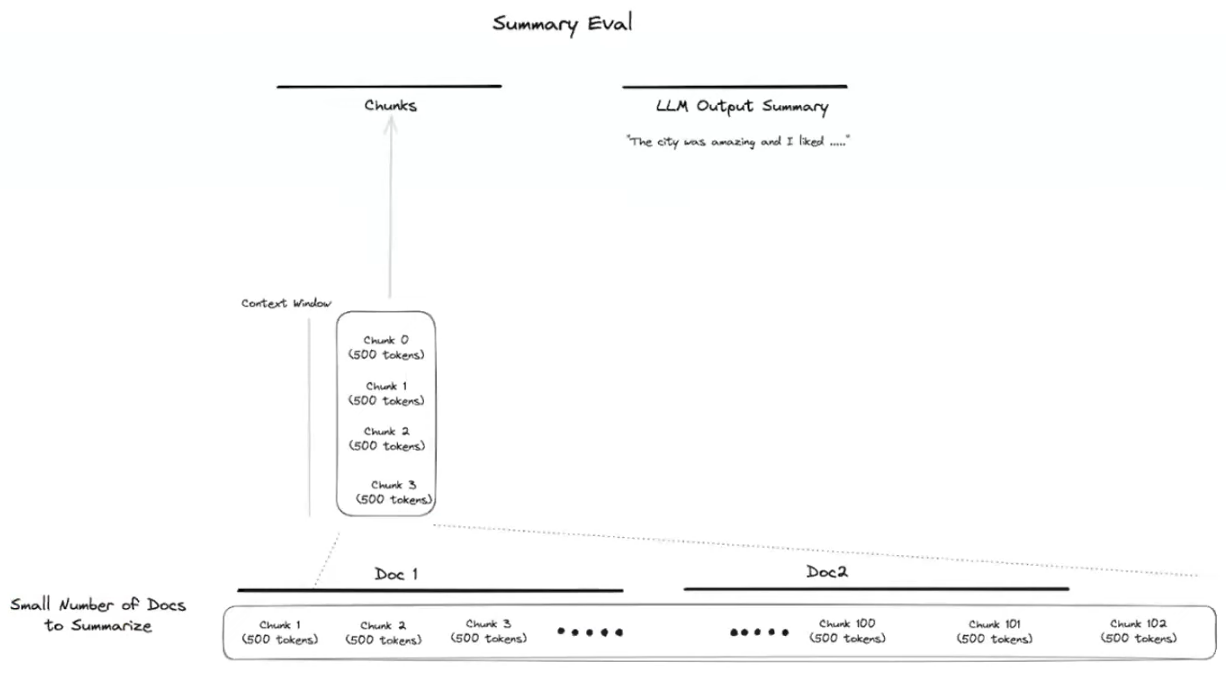
- split into chunks or not (it depends if we use chunks for other use-cases)
- summarize the whole text (the sum of chunks, if chunked)
⚠️ In this case we can use StuffDocumentsChain to summarize into one call with all in it (considering the context size). It is very fast comparing to map reduce or refine.
Summarizing small number of docs when it DOESN'T fit in the context window
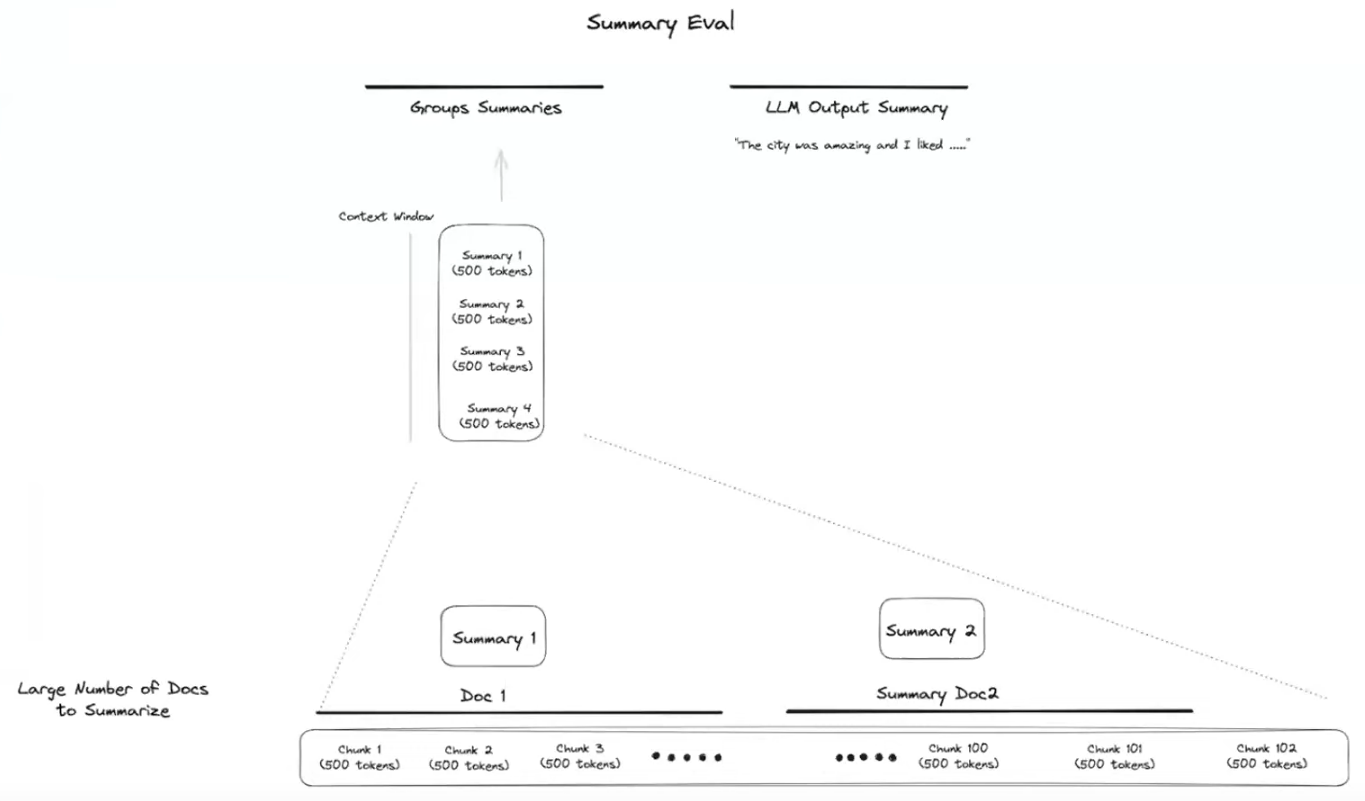
- split into chunks (not necessarily of the same size)
- summarize each document (directly if it fits the context window, or using Map Reduce, Refine or similar algorithm otherwise)
- merge the summaries
- summarize the new "super-chunk"