1. Model Representation / Hypothesis function
The purpose of the model
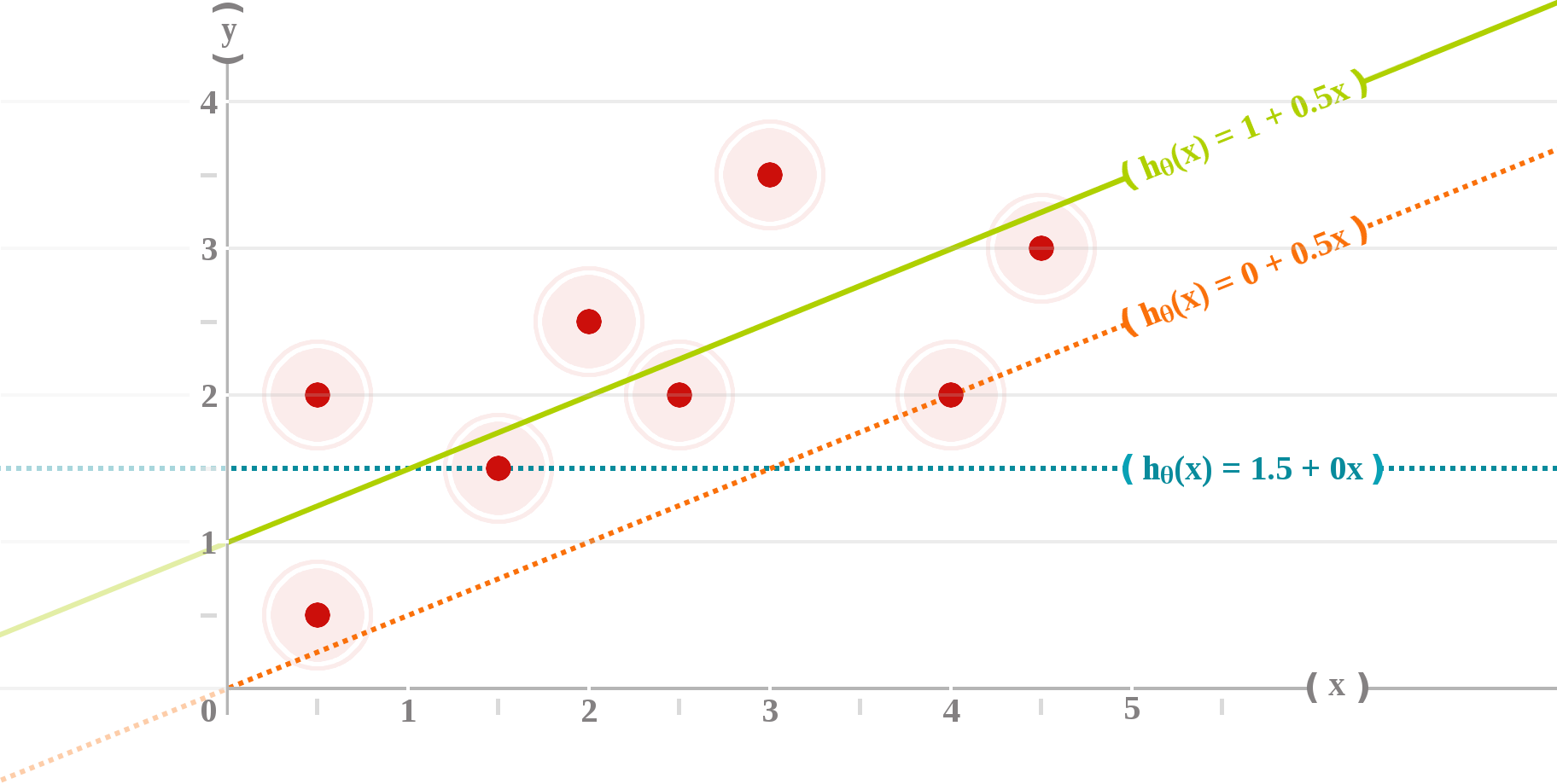
Univariate Linear Regression model
The hypothesis function
ε represents the errors made by the model – it accounts for the fact that the model won't perfectly retrieve the original
values : The vector of errors ε has a normal distribution with a mean equal to 0 and an unknown variance (or covariance in a multivariate model).
Multivariate Linear regression model
The hypothesis function
Using the matrix multiplication representation, this multi-variable hypothesis function can be concisely represented as:
Optimizing the parameters
In order to build a model
2. Cost function
A cost function (or objective function) is a mathematical criterion used to measure how well the hypothesis function performed to map training examples to correct outputs.
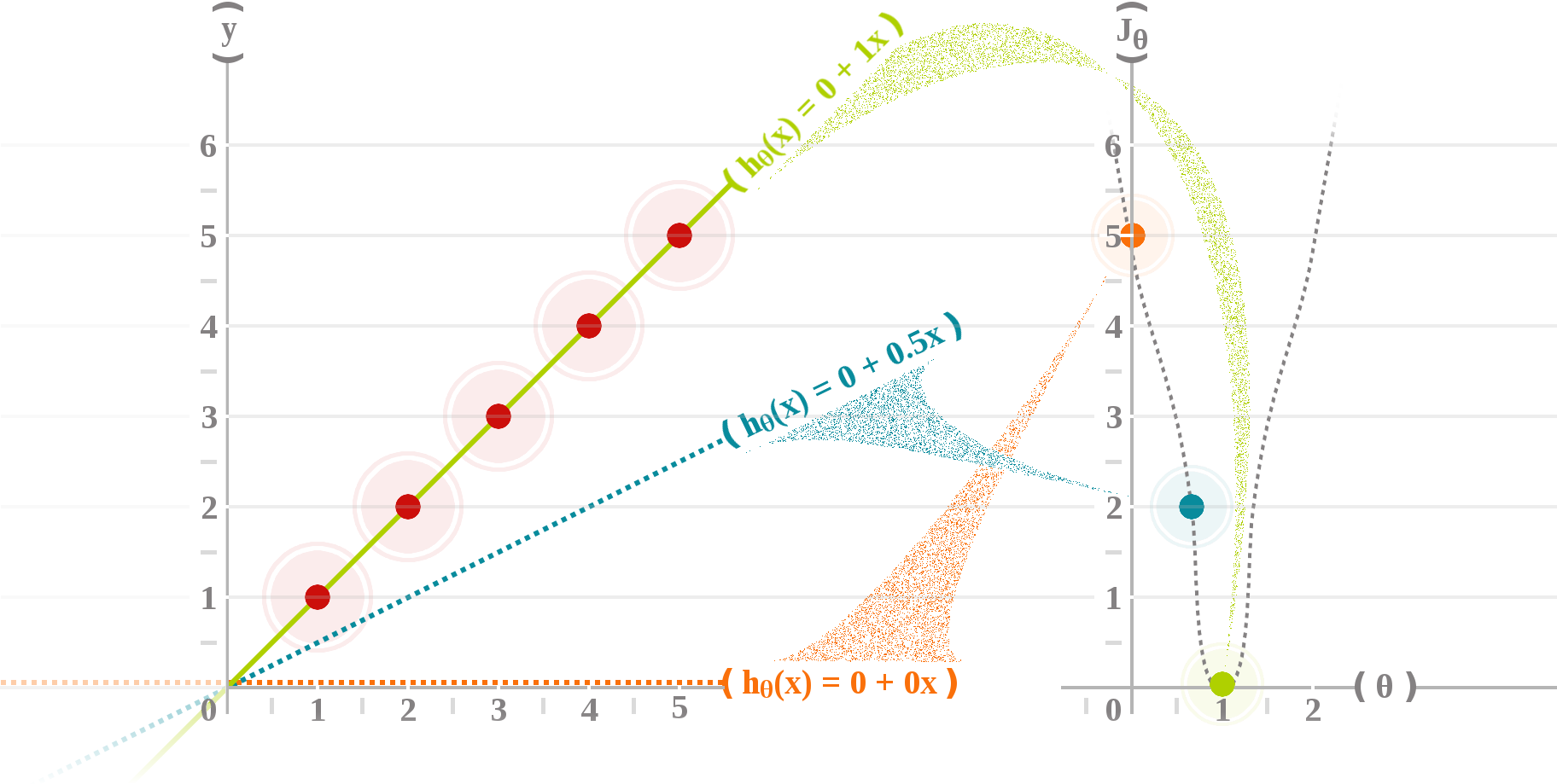
In the best case, the line passes through all the points of the dataset and the cost
Cost functions for logistic regression problems includes :
- Mean Error (ME),
- Mean Squared Error (MSE),
- Mean Absolute Error (MAE),
- Root Mean Squared Error (RMSE),
- Root Mean Squared Logarithmic Error (RMSLE),
- etc.
In practice, the most common cost functions are the Mean Squared Error (MSE) in production (e.g. OLS or Gradient Descent) and the Root Mean Squared Error (RMSE) in analysis. Both lead to the same result, but MSE has one less step, so it's slightly faster, and RMSE has the advantage of having the same unit as the values plotted on the vertical axis and is easier to interpret.
The maximum likelihood estimation is another kind of objective function that is often used in practice. But when such an objective function is used, the goal is to maximize it rather than minimize it.
3. Optimization methods
To build the model
This process of finding the values for which the error
And when it comes to solving such problems there exists both analytical and numerical approaches.
The analytical approach
An analytical solution involves framing the problem in a well-understood form and calculating the exact solution without using an iterative method.
In the case of a linear regression the method that is usually used is the Ordinary Least Squares (OLS) which will compute the
The numerical approach
A numerical solution means making guesses at the solution and testing whether the problem is solved well enough to stop iterating.
In the case of a linear regression the method that is usually used is the Gradient Descent which will iterate over the
This technique is a little excessive for univariate regression (as OLS is simpler), but its definitely useful for multivariate regression.
Advanced Optimization
There exists several algorithms to optimize the
Here is a short list of the most often used optimization algorithms:
- Conjugate Gradient
- BFGS (Broyden–Fletcher–Goldfarb–Shanno)
- L-BFGS (Limited-memory BFGS)
These optimization algorithms are usually faster, and they remove the hassle to manually pick
OLS (Normal Equation) vs Gradient Descent
| OLS (Normal Equation) | Gradient Descent |
|---|---|
| No need to choose |
Need to choose |
| No need to iterate | Needs many iterations |
| Find exact solution (most of the time...) | Makes guesses |
| No need to feature scaling | Feature scaling should be used |
| Slow if |
Works well when |
(for vectorized version) (for non-vectorized version) |