#evaluation #multi-metric #llm
HELM adopts a top-down approach explicitly specifying the scenarios and metrics to be evaluated and working through the underlying structure.
There are 16 core scenarios, each defined by a tuple of (task, domain, language, ... ).
- Tasks - include question answering, summarization, information retrieval, toxicity detection.
- Domains - could be news and books,
- Language - could be English, Spanish etc.
- ...
The 16 core scenarios include 6 user-oriented tasks such as question answering, information retrieval, summarization, and toxicity detection, spanning a range of domains and English dialects.
The 26 supplementary scenarios to thoroughly investigate particular aspects, such as linguistic understanding, world and commonsense knowledge, reasoning abilities, memorization and copyright concerns, disinformation generation, biases, and toxicity generation.
There are 7 different metrics for technical and societal considerations:
- accuracy,
- robustness,
- calibration,
- fairness,
- bias,
- toxicity,
- efficiency.
The following diagram shows how HELM is improving the granularity for LLM evaluation.
- First, the scenario is decided based on task, domain, user, time, and language.
- Then, the metric itself is multi-threaded, including input perturbation such as typo (Robustness), gender dialect (Fairness), and output measures such as Accuracy (ROUGE, F1, Exact Match), Toxicity, Efficiency (denoised).
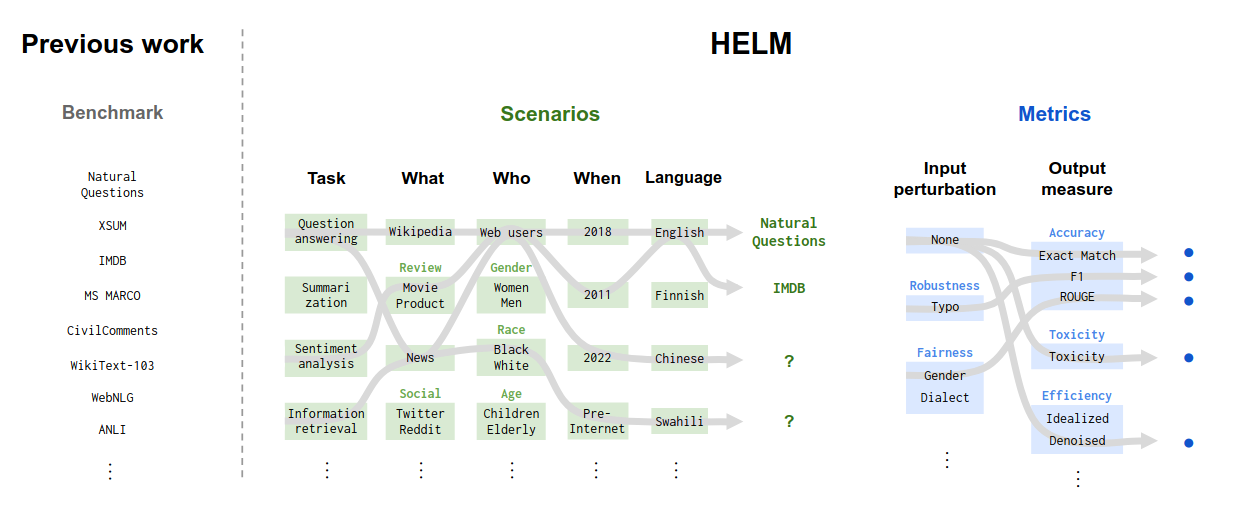
Figure: The importance of the taxonomy to HELM.
Previous language model benchmarks (e.g. Super GLUE, LM Evaluation Harness, BIG-Bench) are collections of datasets, each with a standard task framing and canonical metric, usually accuracy (left).
In comparison, in HELM we take a top-down approach of first explicitly stating what we want to evaluate (i.e. scenarios and metrics) by working through their underlying structure. Given this stated taxonomy, we make deliberate decisions on what subset we implement and evaluate, which makes explicit what we miss (e.g. coverage of languages beyond English).
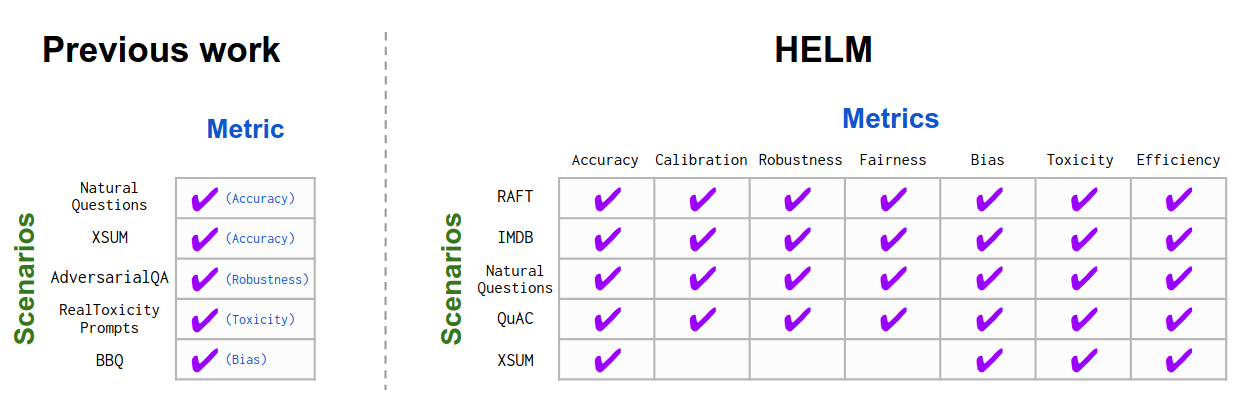
Figure: Many metrics for each use case.
In comparison to most prior benchmarks of language technologies, which primarily center accuracy and often relegate other desiderata to their own bespoke datasets (if at all), in HELM we take a multi-metric approach. This foregrounds metrics beyond accuracy and allows one to study the tradeoffs between the metrics.

Figure: Standardizing language model evaluation.
Prior to our effort (top), the evaluation of language models was uneven. Several of our 16 core scenarios had no models evaluated on them, and only a few scenarios (e.g. BoolQ, HellaSwag) had a considerable number of models evaluated on them.
Note that this is cumulative: in the top plot, we not only document instances where the work introducing the model evaluated on a given scenario, but any subsequent work evaluated the model on the scenario (e.g. Tay et al. (2022a) in the paper on UL2 (20B) expanded the evaluation of T5 (11B) to include HellaSwag and several other datasets) under any conditions (e.g. fine-tuning, 0-shot prompting, 5-shot prompting).
After our evaluation (bottom), models are now evaluated under the same conditions on many scenarios.
⚠️ HELM also has a variant for text-to-image evaluation called HEIM
More details here:
- https://arxiv.org/abs/2211.09110
- https://github.com/stanford-crfm/helm
- https://www.youtube.com/watch?v=TkJgc2zGsCc (demo)
- https://www.linkedin.com/pulse/benchmarking-large-language-models-rajat-ghosh-ph-d/
- https://medium.com/aimonks/benchmark-of-llms-part-2-mmlu-helm-eleuthera-ai-lm-eval-e6fc54053e3d