#evaluation #multi-metric #llm
ANLI (Adversarial NLI), is a large-scale Natural Language Inference (NLI) benchmark dataset collected using an iterative, adversarial human-and-model-in-the-loop procedure.
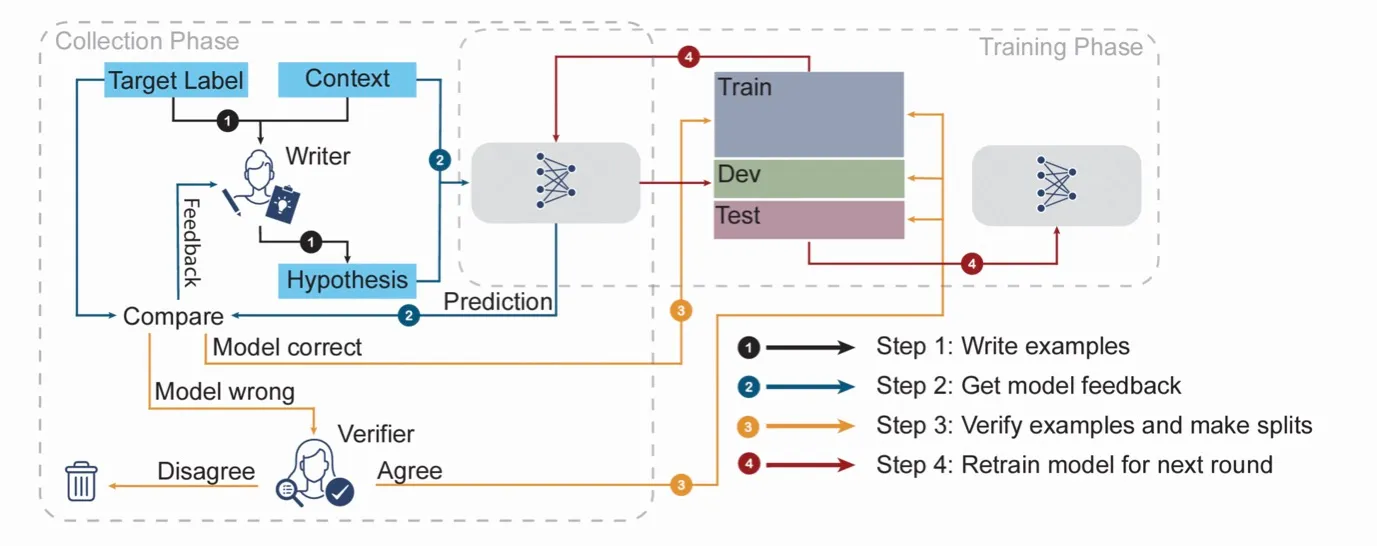
This approach aims to create benchmarks that pose a more difficult challenge while continually learning and evolving over time. In contrast to static benchmarks, ANLI represents a dynamic and evolving target.
Its creation process involves :
- human annotators are devising examples that the currently best models can’t accurately label.
- these “hard” examples, exposing additional model weaknesses, are incorporated into the training set
- these “hard” examples are used to create a stronger model.
- This new model is subjected to the same procedure, thus repeating the process over several rounds.
The iterative process ensures that the dataset gets progressively harder, and the models continually evolve, thereby mitigating benchmark saturation and increasing model robustness.
This Adversarial NLI underlines the potential of iterative, adversarial approaches to push the boundaries of NLU systems. By continually challenging models to improve, we can avoid stagnation in performance benchmarks and stimulate progress in NLU technologies.
Researchers demonstrated that training models on this new dataset leads to state-of-the-art performance on several popular NLI benchmarks.