References and useful ressources
- https://www.promptingguide.ai/techniques
- https://courses.arize.com/courses/llm-observability-search-and-retrieval/
Stages within RAG
-
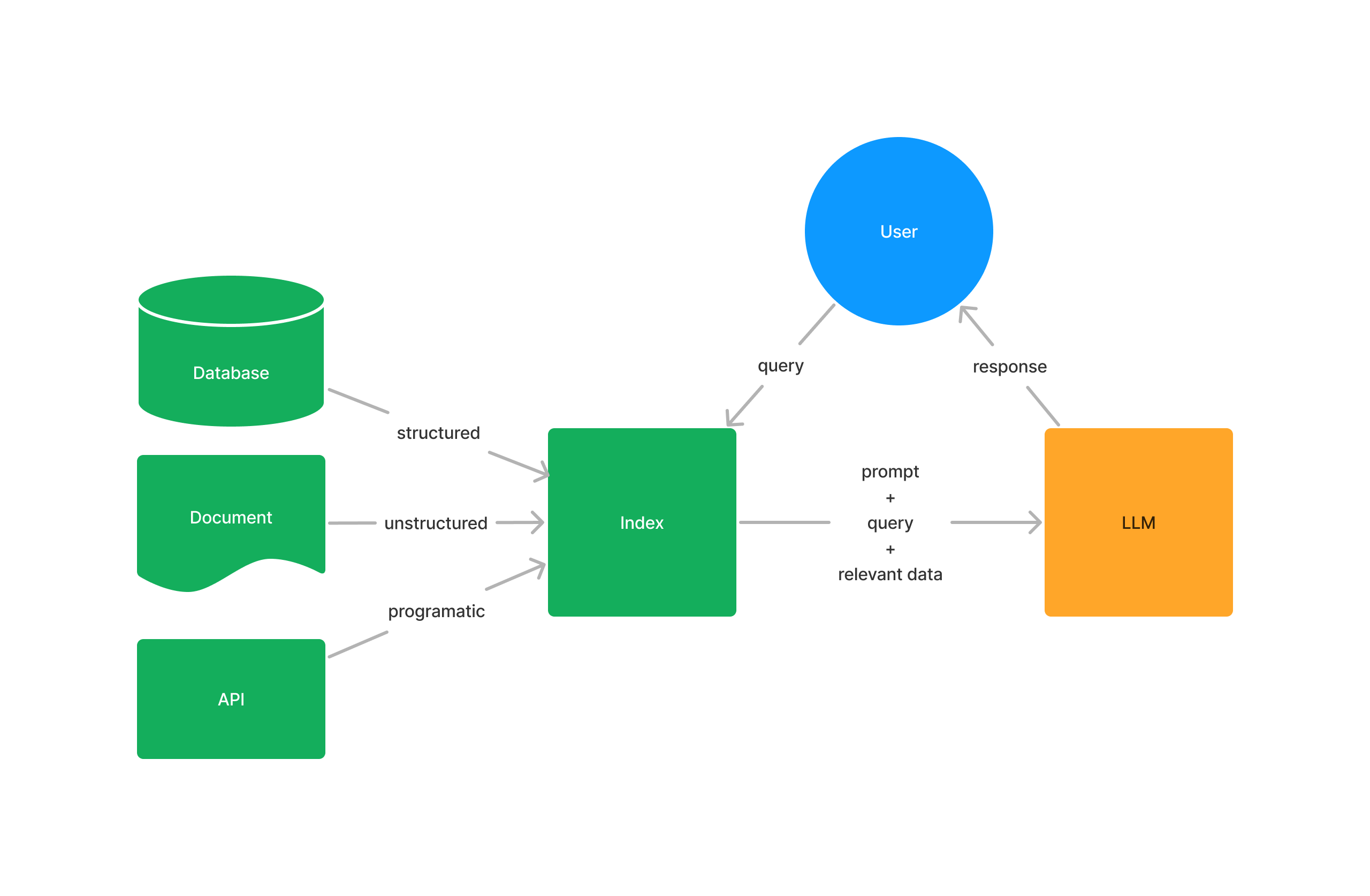
Loading: This refers to getting your data from where it lives - whether it's text files, PDFs, another website, a database or an API - into your pipeline.
-
Indexing: This means creating a data structure that allows for querying the data. For LLMs this nearly always means creating vector embeddings, numerical representations of the meaning of your data, as well as numerous other metadata strategies to make it easy to accurately find contextually relevant data.
-
Storing: Once your data is indexed, you will want to store your index, along with any other metadata, to avoid the need to re-index it.
-
Querying: For any given indexing strategy there are many ways you can utilize LLMs and data structures to query, including sub-queries, multi-step queries, and hybrid strategies.
-
Evaluation: A critical step in any pipeline is checking how effective it is relative to other strategies, or when you make changes. Evaluation provides objective measures on how accurate, faithful, and fast your responses to queries are.
Text-Only RAG vs Multimodal RAG
Text-only RAG
- encode text-only data
- need one encoder for text data
- store the encoded data in an index
- we retrieve text-only from the user-query (text-only) to augment the system-query
- use LLMs to answer questions and evaluate
Multimodal RAG
- encode text as well as image data
- need two encoders: one for text data and one for image data
- store the encoded data in separate index (or namespace/collection) to ease the eval (separate scores)
- we retrieve text and image from the user-query (text and image) to augment the system-query
- use LLMs to answer questions and evaluate
Advanced RAG Querying strategies
⚠️ TODO: explain the strategies
Small-To-Big retrieval
HyDE Query Transform
Multi-Step Query engine
Long LLMLingua
(ReAct) Reason + Act prompting
Used for Common Sense / Math / Problem solving with external tools
ReAct prompts LLMs to generate verbal reasoning traces and actions for a task. This allows the system to perform dynamic reasoning to create, maintain, and adjust plans for acting while also enabling interaction to external environments (e.g., Wikipedia) to incorporate additional information into the reasoning.

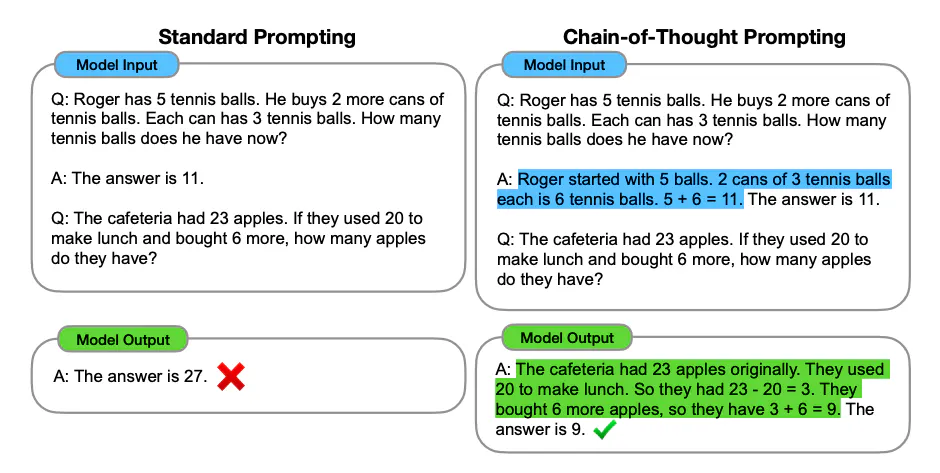
(CoT) Chain of Thought
Used for Common Sense / Math / Problem solving
Enables complex reasoning capabilities through intermediate reasoning steps.
- https://arxiv.org/abs/2201.11903 (CoT)
- https://arxiv.org/abs/2205.11916 (zero-shot CoT)
- https://arxiv.org/abs/2210.03493 (auto CoT)
- https://www.promptingguide.ai/techniques/cot
Few shots CoT
Zero-shot CoT
Another approach is the zero-shot CoT which essentially involves adding "Let's think step by step" to the original prompt.

Auto CoT
Finally, the Auto-GoT try to reduce the difficulty of crafting effective and diverse examples by hand.

(CoD) Chain of Density
Used for Summarization
CoD prompting is a technique designed to optimize summarization tasks in language models. It focuses on controlling the information density in generated summaries to achieve a balanced output. This approach has practical implications in data science, particularly for tasks requiring high-quality, contextually appropriate summaries.
- https://arxiv.org/abs/2309.04269
- https://www.kdnuggets.com/unlocking-gpt-4-summarization-with-chain-of-density-prompting

(CoN) Chain of Nothing
(CCoT) Contrastive Chain of Thought
(Re2) Re-Reading Improves Reading in LLM
Rerankers
⚠️ TODO: Rerankers section